Contents
- Context Explosion — Your Five-Layer Architecture Is Choking the Context
- Why the Old Solutions Aren’t Enough
- Context Engineering — The Real Solution
- Principle 1: JIT (Just-In-Time) Loading
- Principle 2: Token Budgets
- Principle 3: Progressive Disclosure
- Principle 4: Subagent Return Contract
- Five Common Anti-Patterns
- 1. Context Stuffing (Load Everything Upfront)
- 2. Example Bloat
- 3. Duplication
- 4. Unbounded Returns
- 5. Eager Loading
- Back to the Original Question
- When Skills Become Packageable Knowledge Modules
- References


In the previous article we established the five-layer architecture: Command → Agent → Tool + Skill → Context. It looks complete. But if you actually start building an Agent system with this architecture, you’ll hit a wall pretty quickly: The real bottleneck isn’t the architecture design — it’s Context Management. Everyone is busy designing better Agents, combining more Tools, and writing more elegant Skills. But all of that is optimizing the building above ground while the foundation underneath is cracking, shifting, and liable to collapse overnight — because that foundation is the Context Window (and yes, it will blow up on you).
Context Explosion — Your Five-Layer Architecture Is Choking the Context
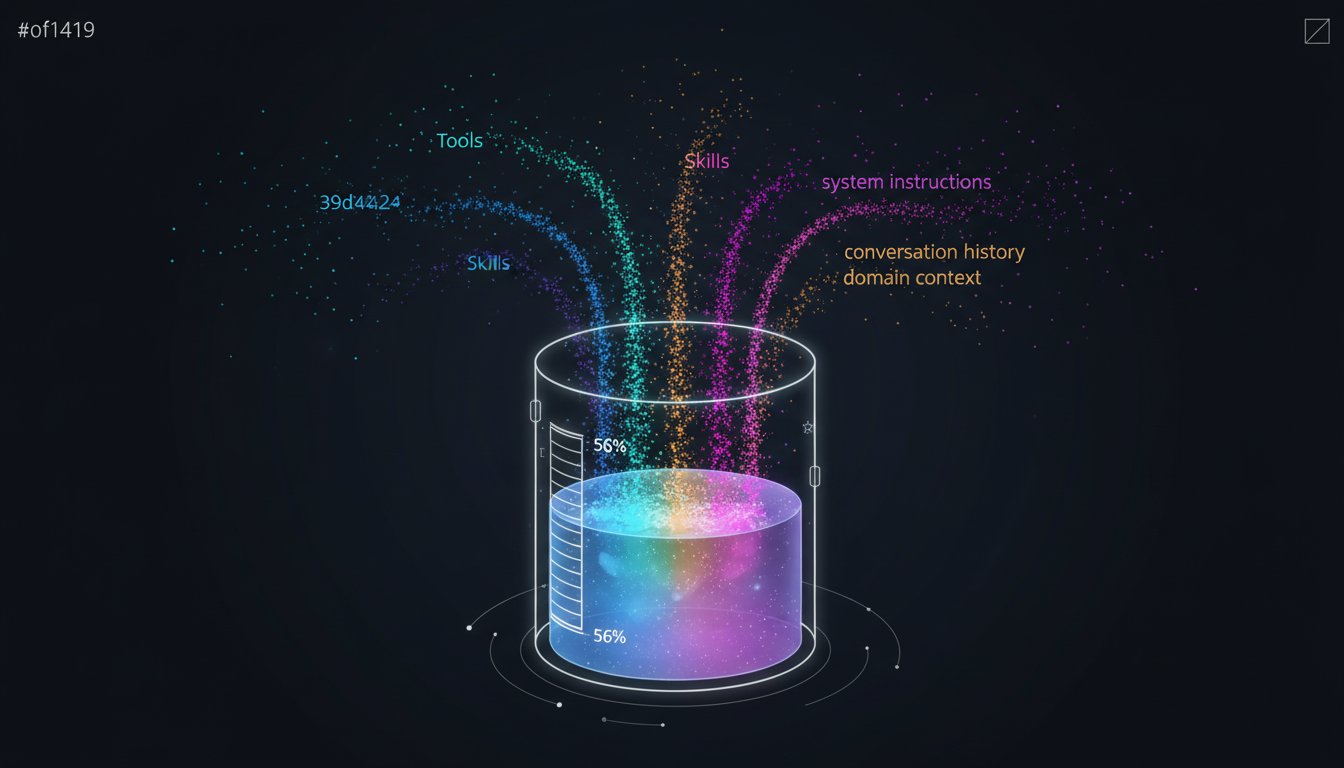
When an AI Agent is running a task, here’s everything that has to fit inside the Context Window simultaneously:
- System instructions (who you are, how you should behave)
- Tool definitions (the schema for every tool)
- Skill knowledge (methodologies, frameworks)
- Domain context (company data, product specs)
- Conversation history (what the user said, what you replied)
- In-progress task state (what’s been done, what still needs doing)
Every layer of the five-layer architecture is pushing things into the Context Window, and the Context Window is finite. If you’re on a company Premium Seat plan, the ceiling is 200K tokens. Sounds like a lot?
It’s really not. A moderately complex task can burn through half of that on Tool definitions and conversation history alone. I’ve tested this myself: loading just the Context I need for a typical work session — no reasoning, no Tool (MCP) calls, no Skill invocations yet — already consumed 24% of the Context right out of the gate. That leaves 76% usable. If you have Auto-Compact enabled, you’re down to around 56% (it usually kicks in somewhere between 78%–83%). More critically: every unnecessary token is actively degrading system performance. It isn’t just “wasting Context space.” Those tokens are noise that interferes with the LLM’s attention, causing it to make worse decisions. And the more complete your architecture is, the faster the Context explodes.

Why the Old Solutions Aren’t Enough
Before Skill Systems existed, how did people deal with this problem?
- Prompt Engineering: Cram all the knowledge into the System Prompt. The problem: prompts get longer and harder to maintain. Your System Prompt grows from 50 lines to 500 lines, and the LLM’s performance actually starts to drop — because it has to dig through a mountain of instructions to find what’s relevant to the current task.
- RAG: Use vector search to pull relevant documents into the Context. The problem: RAG solves “finding relevant data” but not “knowing how to use that data.” You can retrieve 10 relevant documents, but the model still doesn’t know which methodology to apply when analyzing them.
- Agent Frameworks (LangChain, AutoGPT, etc.): Define workflows in code, hardwiring each step. The problem: hardwired workflows throw away the flexibility that makes LLMs valuable in the first place. And every new task type requires a new workflow, which sends maintenance costs through the roof.
All three approaches are trying to solve the same problem, but each only solves part of it. Skills emerged because we needed a mechanism that could give an Agent specialized knowledge without blowing up the Context.
Context Engineering — The Real Solution
If Context Explosion is the root problem, then the solution isn’t “add more stuff” — it’s precisely controlling what gets loaded, when, and how much. That’s Context Engineering. The core problem we’re now solving is:
Find the smallest possible set of high-signal tokens that maximizes the likelihood of the desired outcome.
Principle 1: JIT (Just-In-Time) Loading
Not all knowledge should be loaded at once. In practice we use a three-tier strategy:
Always-on (~500 tokens) ← needed in every conversation
Task-relevant (~2,000 tokens) ← loaded based on task keywords
Reference (~4,000 tokens) ← loaded only when explicitly needed

Always-on is your CLAUDE.md: system identity, core rules, things that never change. This must stay extremely lean because it occupies Context in every single conversation. Task-relevant is loaded dynamically based on the task. When a user asks about financial statement analysis, you load the finance-related Skills and Context. When they ask for a code review, you load the security audit methodology. Reference is the deepest layer of knowledge — it only gets loaded when the Agent explicitly needs to consult it. Most conversations never touch this tier.
Principle 2: Token Budgets
Strategy alone isn’t enough — you need concrete numbers. Here are the budgets used in practice for agents built with pg-agent-dev/agent-ops:
- CLAUDE.md → <60 lines (~500 tokens) — loaded every conversation, must be extremely lean
- Agent definition file → <200 lines — one file, one concern
- Skill main document → <300 lines — summary in the main file, details in subdirectories
- Subagent return → <2,000 tokens — explore deeply, return shallowly
- Context documents → <500 lines — one topic per file, independently loadable
These numbers aren’t arbitrary. Exceed these budgets and system performance starts to degrade.
Principle 3: Progressive Disclosure
A Skill isn’t about cramming a textbook into a prompt. The design core of a Skill is Progressive Disclosure — only loading the depth you need, when you need it. In practice, a well-designed Skill looks like this:
dev-context-engineering/
├── SKILL.md ← summary (~300 lines), always load this first
├── principles/ ← WHY: the reasoning behind the approach
├── patterns/ ← HOW: concrete patterns and practices
├── budgets/ ← LIMITS: token budget tables
├── anti-patterns/ ← DON'T: common mistakes
└── validation/ ← CHECK: checklistsAn Agent doesn’t load the entire Skill directory at once. It reads the SKILL.md summary first to understand what the Skill covers. Only when a task requires deeper knowledge does it go into patterns/ or budgets/ for the details. This is why a Skill isn’t structured like a prompt. A Skill is structured knowledge that can be loaded on demand, at whatever depth the task requires.
Principle 4: Subagent Return Contract
When an Agent dispatches a Subagent to do deep research, the Subagent should not dump everything it found back to the parent. The correct pattern is “explore deeply, return only what’s needed.” The Subagent uses its full Context to explore, but returns only a structured summary (<2,000 tokens). This protects the parent Agent’s Context Window.
This is the most common failure mode in multi-Agent systems: the Subagent does thorough research, happily returns everything it found, and blows up the parent Agent’s Context. Every subsequent task in that session runs noticeably worse.
Five Common Anti-Patterns

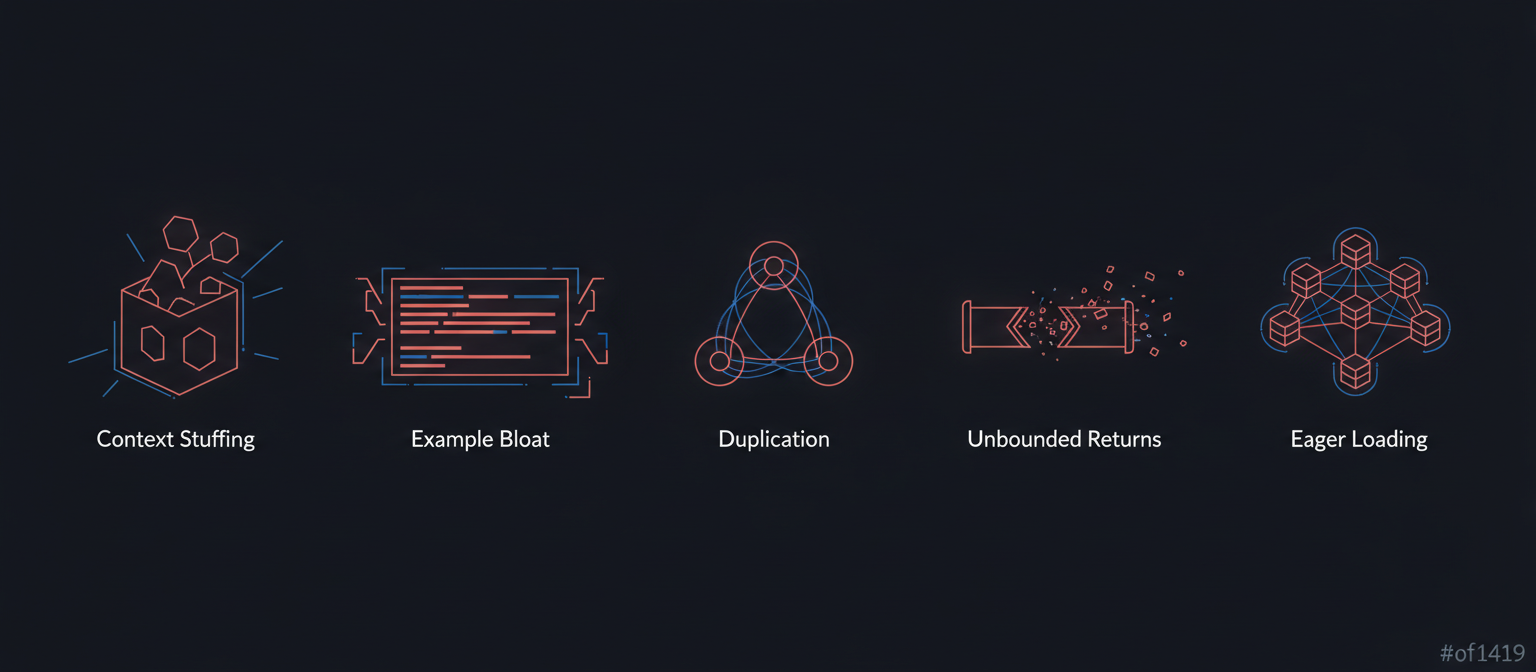
The five most common Context Engineering anti-patterns:
1. Context Stuffing (Load Everything Upfront)
“Load everything first — the Context Window is huge anyway.” This is the most common and most damaging mistake. 200K tokens sounds like a lot, but noise drowns out the signals the model actually needs to pay attention to. LLM attention is finite. The more irrelevant content you pack in, the worse it processes the relevant content.
2. Example Bloat
Cramming more than two inline code examples into CLAUDE.md or a Skill. Examples are expensive in tokens, and LLMs tend to over-imitate the format of examples — which actually reduces flexibility.
3. Duplication
The same piece of knowledge appearing in CLAUDE.md, a Skill, and a Context document simultaneously. This makes maintenance a nightmare and wastes tokens. Each piece of knowledge should live in exactly one place.
4. Unbounded Returns
A Subagent finishes its research and throws everything back to the parent. This is exactly why the Subagent Return Contract exists. Returns without an upper bound will destroy the originating parent Agent’s Context.
5. Eager Loading
Regardless of the task, loading all Skills and Context upfront. The effective approach is JIT: first understand what the task is, then decide what to load.
Back to the Original Question
The last article ended with a question: why are almost all AI Agent systems adding a Skill system?
The answer should be clear now. It’s not because LLMs aren’t smart enough. It’s because the Context Window is finite — you can’t stuff all possible knowledge into a prompt. Skills provide a mechanism for:
- Structured knowledge — not a wall of text, but a knowledge module with a directory structure
- Progressive Disclosure — load the summary first, load details only when needed
- JIT loading — dynamically decide what to load based on the task
- Reusability — the same Skill can be used by different Agents across different tasks
At its core, a Skill is an expert module — a way to turn a general-purpose LLM into a domain specialist exactly when needed. And Context Engineering is the operating system that manages those expert modules.
When Skills Become Packageable Knowledge Modules


If you’re an engineer, you’ll notice that the design of Skills looks a lot like:
- VSCode Extensions
- Browser Plugins
- NPM Packages
Each Skill is a Domain Expertise Package — packaged professional knowledge that can be installed, updated, and shared.
There’s one critical difference though. Traditional plugins are code. Skills are knowledge. A plugin tells a computer “how to execute.” A Skill tells an AI “how to think.”
So when Skills become packageable, shareable knowledge modules, something new starts to emerge in the AI space: a Plugin Economy.
We could soon see things like:
- Legal Skill — letting AI review contracts the way a lawyer would
- Security Skill — letting AI conduct penetration testing the way a security expert would
- Finance Skill — letting AI interpret financial statements the way an analyst would
But this also introduces a new question: who defines the rules of this ecosystem? Who controls the standard for Skills?
Right now, MCP is solving the cross-platform problem for Tools, letting different Runtimes share a common toolset. But there’s no standard answer yet for the cross-platform problem for Skills. This means the future competition in AI may not just be about models — it may be about Skill ecosystem competition. That’s what the next article is about.
References
[1] Anthropic: “Effective Context Engineering for AI Agents” — “Good context engineering means finding the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome” https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
[2] “Lost in the Middle: How Language Models Use Long Contexts” — Liu et al. (Stanford/TACL 2024) — Academic paper demonstrating that model performance on information in the middle of long contexts drops significantly https://arxiv.org/abs/2307.03172
[3] Chroma Research: “Context Rot” — Tests 18 frontier models; all showed performance degradation as input length increased; three compounding mechanisms: lost-in-middle, attention dilution, and distractor interference https://research.trychroma.com/context-rot
[4] Andrej Karpathy on Context Engineering — “When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window” https://x.com/karpathy/status/1937902205765607626
[5] Anthropic: “Equipping Agents for the Real World with Agent Skills” — Describes three-tier progressive disclosure: load the description at startup, load the full SKILL.md only when task-relevant https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills
[6] Martin Fowler: “Context Engineering for Coding Agents” — “An agent’s effectiveness goes down when it gets too much context”; models hit a performance ceiling around 1 million tokens https://martinfowler.com/articles/exploring-gen-ai/context-engineering-coding-agents.html
[7] Simon Willison: “Context Engineering” — Covers concrete techniques including Context Quarantine, Context Pruning, and Context Summarization https://simonwillison.net/2025/Jun/27/context-engineering/
Support This Series
If these articles have been helpful, consider buying me a coffee