Contents
- L0-L2: Where the OS Framework Works Perfectly
- But It Breaks Down at L3: OS Processes All Look the Same, My Agents Don’t
- Problem 1: Shell Hooks Can’t Extract LLM Judgments
- Problem 2: Filesystem IS the Result
- Problem 3: Unified Format Is Meaningless Across Heterogeneous Agents
- Problem 4: The Receiver’s Context Degrades
- Problem 5: Identity Loading Is a Dimension OS Never Had
- Five Problems, Five Answers the OS Framework Doesn’t Have
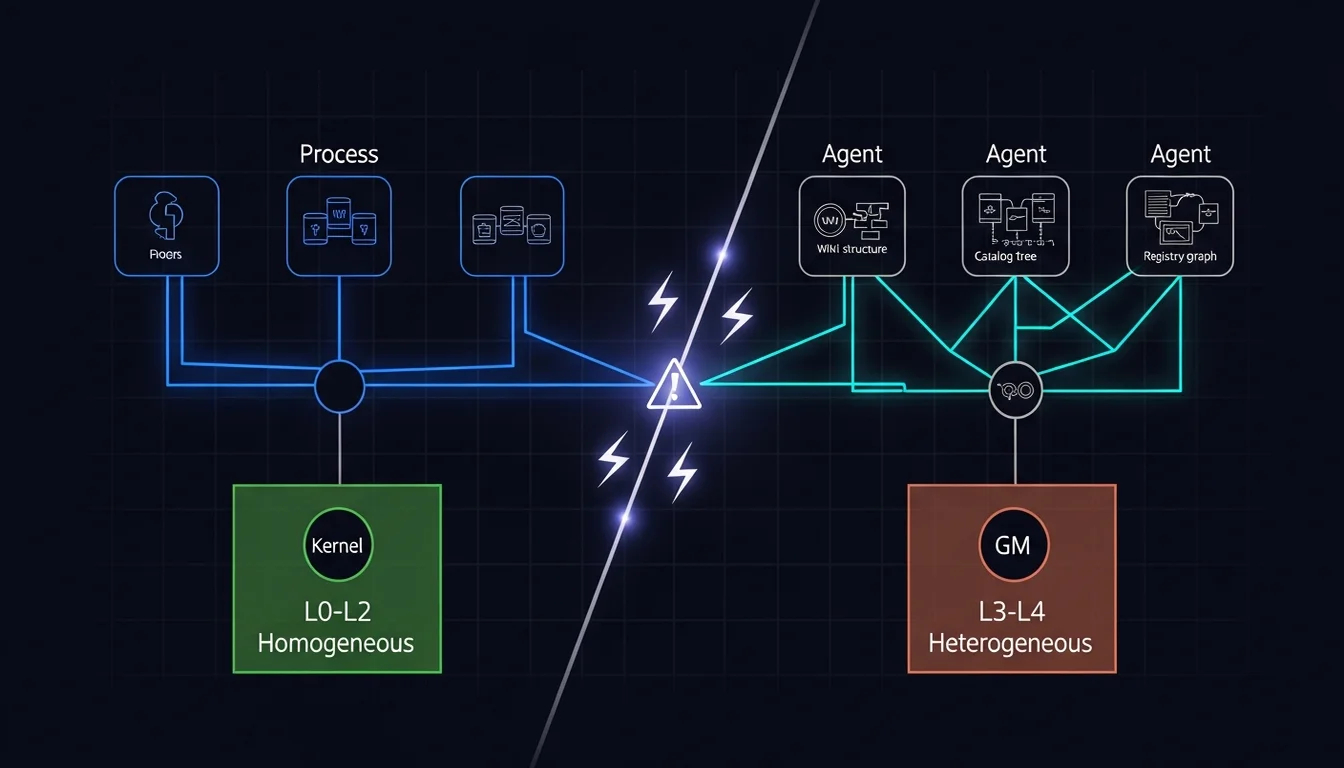
- Homogeneous vs. Heterogeneous: The Most Fundamental Difference

In one line: The foundation of Agent communication is OS IPC — but OS assumes all processes are built the same, and none of my Agents are.
While building the Agent Team, I had a feeling early on that the communication problems I was running into felt familiar — like I’d seen them somewhere before.
In November, when my Agent architecture hit its fourth iteration, I remembered: these architectures and problems actually already exist in the OS framework. How do processes pass data to each other? IPC — Inter-Process Communication. Pipes, shared memory, message queues, file locks. I’d touched all of these concepts in my OS coursework (even though at the time I never imagined I’d one day use them to design AI Agent communication architectures).
So I went back to the material and understood the OS framework, but I didn’t copy the OS approach. I could still see some gaps: the concepts made sense, but actually landing them was still something I had to figure out myself. So I decided it would be better to let my own design grow step by step from implementation. The two dispatch paths in Part 5, the three hybrid modes (Mode A / B / C), hook chains, inbox/outbox — none of these were derived from a textbook. They were dug out of concrete frustrations and failures: “Em was spawned without knowing she was Em,” “GM kept forgetting to cd,” “the hook format was wrong but nothing errored.” And because of that, I later forgot about the OS frame for a while.
Two weeks ago, a colleague brought this idea up again, in a more refined way, so I wrote a side story from his perspective. But unlike a few months ago, this time I had the Agent Team. So I asked Em to ingest the OS framework — the five-layer decision model introduced in the previous side story. I wanted to see whether, after all these months, I had still been walking down that path. The result: my lower-layer choices (L0-L2) were already right and aligned with the framework, but the upper layers (L3-L4) still had problems the OS framework couldn’t solve — because OS assumes all processes are homogeneous, and every Agent in my team is heterogeneous.
L0-L2: Where the OS Framework Works Perfectly
Looking back at the five-layer decision model from the side story (L0 Environment → L1 Transport → L2 Topology → L3 Protocol → L4 Content Contract), there are some interesting things in it. But if you skipped that article, let me quickly summarize where my Agent Team sits on the bottom three layers and how those choices map to the OS framework:
- L0 = Same machine (all Agents are Claude Code sessions running on the same Mac)
- L1 = File I/O (inbox/outbox directories + pipe for subagents; file is the most debuggable transport on same machine —
cat inbox/and you can see everything) - L2 = Star (GM) + limited peer (GM handles central coordination; Agents can communicate directly through the filesystem for core work)
These three choices are actually quite consistent with OS framework experience. Of course, at the time I wasn’t consciously “applying the OS model” when making them. I derived them from real scenarios. The silent failures in Part 5 showed me the debug advantages of file I/O; the hybrid topology grew out of watching GM become a bottleneck. Looking back now, the five-layer model gave me some reassurance and confirmed that the direction I had taken was right.
But It Breaks Down at L3: OS Processes All Look the Same, My Agents Don’t
L0-L2 is tidy. The OS IPC framework applies perfectly. But at L3 (Protocol) and L4 (Content Contract), I found that the OS framework no longer fit — and the reason is fundamental: OS processes are homogeneous; my Agents are heterogeneous.
In an OS, no matter what program a process is running, it lives under the same kernel, uses the same syscalls, and is managed by the same scheduler. The difference between processes is only “what program they run,” but their operational framework is consistent. So from the OS framework’s point of view, we can handle IPC with a unified protocol. Whether you’re a web server or a database, a pipe is a pipe, a signal is a signal.
But in the current Agent Team, every Agent has a different architecture, Context structure, and workflow:
Em has her own wiki structure (four page types: concepts / entities / sources / analysis) and three commands (ingest / query / lint). Her Context regularly carries cross-references across a dozen concept pages.
Dm has three subagents (Architect uses Opus for design, Scaffolder uses Sonnet to build, Validator uses Sonnet to verify). His Context flows as a pipeline: Architect’s plan goes to Scaffolder, Scaffolder’s output goes to Validator.
C7 has a catalog index and a provisioning mechanism. His job is maintaining the canonical location of shared skills and pushing them to other Agents.
G7 has a registry and fleet management. He manages Layer 3 external Agents with a sacred boundary (only he can talk to Layer 3).
These Agents aren’t “programs running different code under the same kernel.” They’re more like “machines running different operating systems, connected to the same network by coincidence” — each with entirely different internal architecture, file systems, and operational logic. I can’t use a single unified protocol to handle their communication, because what each one produces after finishing work looks completely different.
That heterogeneity creates five problems the OS framework can’t solve:
Problem 1: Shell Hooks Can’t Extract LLM Judgments
When an OS process exits, it can use exit codes to tell the caller “success or failure,” and stdout to pass results back. That’s the standard OS approach.
From the very beginning, we designed the Level 1 Completion Report with the same kind of clean, standard framework. By default, every Agent would automatically write a structured completion report to GM’s inbox when it finished, including agent name, task description, result (complete / partial / failed), number of files changed, and a Flag field (write a line if anything unusual came up).
As I said earlier, beautiful design. But in practice, the Flag field was never used once.
The reason: a Stop hook is a shell script. It can only write static JSON — timestamps, agent names, fixed fields. It can’t extract LLM judgments. A Flag field like “what’s worth noting from this task?” requires reasoning, and shell scripts can’t fill that in. By the time the hook fires, the Agent’s session is already over — the AI model is gone. You can’t ask it anything.
An OS process can write its judgment to stdout before exiting. But an Agent’s “judgment” lives in the model’s Context — and by the time the hook triggers, that Context has already vanished. An Agent ending its session isn’t like a process terminating. It’s the death of a stateful thinker, not the shutdown of a stateless program.
Problem 2: Filesystem IS the Result
The more fundamental issue: even if a Level 1 Report could be written, it would be redundant.
When an OS process finishes, its result usually lives somewhere that’s hard to inspect directly — a row in a database, an address in memory, a binary file. The caller can’t just “read” the result, so the process needs to write a descriptive report: “I wrote 3 records to table X,” “the computed value is Y.” Report and result are two separate things.
But the Agent Team is different. When Em finishes an ingest, the new wiki pages are right there in the wiki/ directory — open them and you get structured markdown. When Dm finishes scaffolding, the new Agent’s directory structure is right there, CLAUDE.md open for reading. When C7 finishes provisioning, the skill files are in the target Agent’s .claude/skills/. Every Agent’s output is itself a human-readable and GM-readable artifact. You don’t need the Agent to write a summary of “which pages I created, which settings I changed” — the output is self-describing.
GM does need to know “where to look” (that’s the inspection map, which we’ll get to next), but once he gets there, he’s looking at the result itself — not a description of it. In OS, “report” and “result” are separated (you describe the result via stdout, while the result itself is elsewhere). In the Agent Team, they’ve collapsed into one. What the Agent writes to the filesystem is its output. No additional reporting protocol needed.
Problem 3: Unified Format Is Meaningless Across Heterogeneous Agents
OS can use a unified message format for IPC because the differences between processes are in content, not structure. But my Agent Team’s output structures are inherently different:
- Em’s output: wiki pages (with frontmatter, cross-references, concept categorization)
- Dm’s output: directory structures (CLAUDE.md + skills/ + commands/ + settings.json)
- C7’s output: catalog entries + provisioned skill files
- G7’s output: registry entries + health state
How would you describe four completely different things with one unified report format? Forcing a unified format just makes every Agent compress its output into a generic summary, throwing away the most valuable structured information.
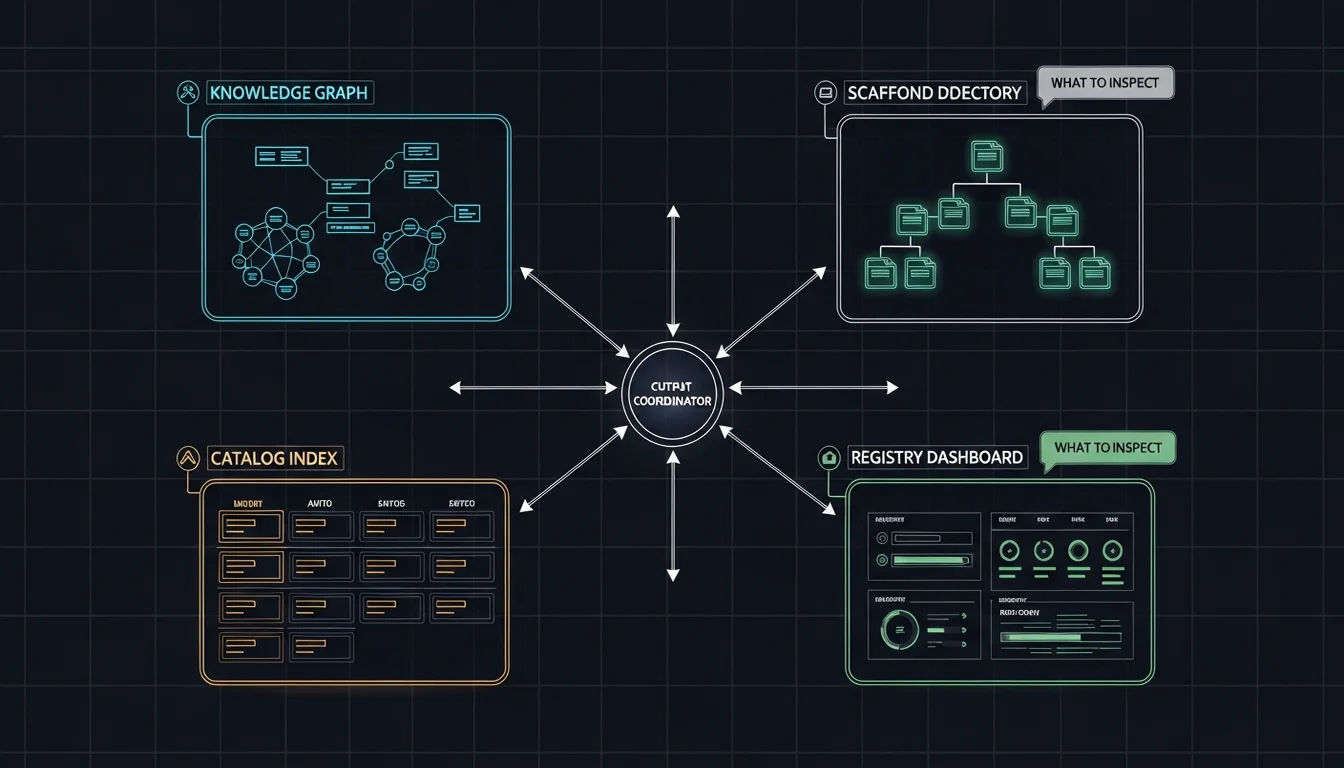
So instead of a unified format, I did the opposite — I built an inspection map that tells GM where to look and what to look for, per Agent:
| Agent | Where to look | What to check |
|---|---|---|
| Em | wiki/log.md, newly created/updated pages | Correct source summary, concept extraction, cross-reference updates |
| Dm | Scaffolded directories, modified agent files | Structure matches design, skills wired up, quality gates passed |
| C7 | catalog/INDEX.md, provisioned skill directories | Catalog entry complete, skill correctly pushed to target |
| G7 | registry/agents.md, agent health state | Agent registered, dispatch validated, health state normal |
This is more precise and more complete than any unified report format — because GM is looking at the Agent’s actual output, not a summary the Agent wrote. And Agent-written summaries have a way of missing things or putting a positive spin on them.
Problem 4: The Receiver’s Context Degrades
When an OS process receives an IPC message, it doesn’t get “dumber” because the message is long. An Agent does.
An Agent’s Context window is finite. Every extra token occupies reasoning space, and LLM attention mechanisms mean that too much irrelevant context reduces the model’s focus on what matters [1]. So Agent-to-Agent communication isn’t just about “did it arrive” — it’s also “once it arrives, can the receiver use it effectively?”
This is why L4 (Content Contract) in the five-layer model matters far more in Agent communication than in OS IPC. In OS, L4 is almost a non-issue — bandwidth and memory usually aren’t the bottleneck. In Agent systems, L4 is where things succeed or fail. If an Agent sends a raw context dump to another Agent, the receiver’s context window explodes and reasoning quality drops off a cliff.
That’s why I designed the Return Contract (explore deep, return shallow) early on: Level 1 reports cap at 200 tokens, Level 2 at 2000 tokens. No matter how much data an Agent processed internally, what it returns to GM is always compressed. If GM needs more, he reads the designated files. This is the same principle as Subagent design — the Context flow rules from Part 5 — just extended to all Agent-to-Agent communication.
Content Contract is, at its core, Context Engineering extended to the communication layer. Whatever principles you use to manage an Agent’s own Context (JIT loading, token budgets, selective loading) — those same principles should govern what Agents send each other.


Problem 5: Identity Loading Is a Dimension OS Never Had
When an OS process is forked, it inherits the parent’s environment and then execs its own program. That process doesn’t need to “load an identity” — because a process doesn’t need to know who it is in order to work.
An Agent does. And this took up a lot of space in both Part 2 (Identity) and Part 5 (Dispatch). Em has to load her own CLAUDE.md (her methodology and constraints), her own Skills (wiki-schema), and her own Commands (ingest / query / lint). If she loaded GM’s CLAUDE.md instead, she’d think through GM’s reasoning framework and produce the wrong results.
The five-layer model has no “identity loading” dimension, because that’s an Agent-specific problem. An OS process doesn’t need to “know who it is.” But every judgment an Agent makes is shaped by its identity (CLAUDE.md). Identity isn’t just metadata — it’s the Agent’s reasoning framework. Loading the wrong identity isn’t a “wrong name” problem. It’s “making every decision with the wrong logic.”
This is the fundamental reason I needed Hybrid Dispatch (Mode A / B). Option A (Agent Teams) has cwd inheritance constraints that prevent Agents from loading their own identity, so Option B (CMUX split-pane) lets each Agent start in its own directory and natively load everything that belongs to it. This isn’t a performance consideration or an architecture preference — it’s a design the identity loading requirement forced into existence.
Five Problems, Five Answers the OS Framework Doesn’t Have
Looking back, each of the five problems grew its own solution that doesn’t appear in any OS textbook:
| Problem | OS approach | My approach | Why they differ |
|---|---|---|---|
| Result extraction | exit code + stdout | Filesystem IS the result | LLM is gone by the time the Agent exits — can’t write stdout |
| Result presentation | Unified message format | Inspection map (per-agent output domain) | Each Agent’s output structure is inherently different |
| Transmission quality | Doesn’t affect receiver’s processing capacity | Return Contract (< 200 / 2000 tokens) | Context window is finite; extra tokens degrade reasoning |
| Identity | Process inherits parent env | Hybrid Dispatch (Option B lets Agent start in its own directory) | Agent identity shapes reasoning framework, not just metadata |
| Scheduling | Unified scheduler manages all processes | Three dispatch modes (A / B / C) + human judgment gate | Heterogeneous Agents can’t be managed by a single rule |
L0-L2 is OS IPC’s domain. The five-layer model provides the right analytical framework and validation there. At L3-L4 and identity loading, what’s needed is Agent-specific design thinking. OS experience can point a direction (“keep the protocol thin,” “compress what you transmit”), but the specific solutions — inspection map instead of reports, token limits in the Return Contract, Hybrid Dispatch for identity loading — those answers aren’t in any OS textbook.
Throughout the process of building my Agent Team, without knowing the five-layer model existed, I had already worked through all the problems the OS framework can’t solve. The model’s value wasn’t teaching me how to design — it was validating that my lower-layer design was correct, and helping me clearly see where the upper-layer challenges diverge from OS.
Homogeneous vs. Heterogeneous: The Most Fundamental Difference
If you had to capture the fundamental difference between OS IPC and Agent communication in one sentence, it’s this:
OS manages homogeneous processes. An Agent Team manages heterogeneous specialists.
An OS scheduler can manage all processes with the same rules because the process interface is uniform — every process has a PID, responds to signals, can be killed. But an Agent Team’s coordinator (GM) can’t manage all Agents with the same rules, because every Agent’s capabilities, workflows, Context structure, and even ways of thinking are different. GM needs to understand, per Agent, “what it produces,” “where to look,” and “how to judge quality.” That’s per-agent knowledge, not a per-process unified interface.
This also explains why my dispatch ended up as three modes (A / B-Chain / C-Notify) rather than one unified dispatch mechanism. Different Agent combinations, different task types, different Context flow requirements — all of it means “how to dispatch” is itself a judgment call each time. Does the intermediate output need to stay in GM’s Context? Is the next step predetermined or does GM need to decide? An OS scheduler never has to make those calls, because OS processes don’t “load the wrong identity” or “blow up their Context” based on how they were dispatched.
Maybe what OS IPC can give me is “how people solved this before” — so I don’t start from zero, and can stand on decades of OS design thinking. Know to use file on the same machine, know to use a hybrid topology, know to keep the internal protocol thin and the external protocol thick.
But what OS IPC can’t give me is: “when your processes have their own thoughts and memories, how does the nature of communication change?” — because we’re not passing bytes. We’re passing context. And context has quality, capacity, and the risk of degradation.
That’s why my Agent Team ultimately grew things the OS framework doesn’t have: inspection map, Return Contract, Hybrid Dispatch, per-agent output domains. These designs don’t reject OS wisdom — they build on it, and then go further to handle a problem AI Agents have to face that OS never did: the things you’re managing can think, and every one of them thinks differently.
References
[1] arXiv — Solving Context Window Overflow in AI Agents (on how context window size affects reasoning quality)
[2] AI Pace — Context Engineering: Mitigating Context Rot in AI Systems (“the larger the context, the lower the model’s reliability”)
[3] FINOS — Multi-Agent Trust Boundary Violations (cascading effects of scope violations)
[4] Anthropic — Effective Context Engineering for AI Agents
Support This Series
If these articles have been helpful, consider buying me a coffee