

In one line: The core work of building an Agent Team is defining specs, not writing code.
97% Markdown: The Most Counterintuitive Metric
Seven days later, I looked back at the data and one number stopped me cold: across all files produced by this Agent Team, 97% were Markdown.[3]
31 sessions, 292 hours of interaction time, 487 messages I sent, 3,525 AI responses, 325 files modified, over 20,000 lines of new content — and among all tagged language types, 1,150 out of 1,242 were Markdown. The proportion of actual code was vanishingly small.
I originally assumed “building an Agent Team” was an engineering task — I’d write lots of TypeScript or Python, handle API integrations, do database migrations, build communication pipelines. But what I was actually doing was: writing CLAUDE.md to define each Agent’s identity, writing METHODOLOGY.md to define each Agent’s thinking framework, writing Skill documents to define each Agent’s capabilities, writing wiki pages to accumulate cross-Agent shared knowledge, writing contract documents to define asset quality standards, writing state files to record the team’s real-time status. The actual code was for a later phase — it had nothing to do with the core of this Agent Team.
1,080,005 output tokens, roughly equivalent to 800 pages of a book, and those 800 pages were almost entirely natural-language specs and knowledge — not code.
| Metric | Data |
|---|---|
| Sessions | 31 |
| Interaction time | 292 hours |
| Human messages | 487 |
| AI responses | 3,525 |
| Files modified | 325 |
| New content | 20,000+ lines |
| Output tokens | 1,080,005 (≈ 800 pages) |
| Markdown ratio | 1,150 / 1,242 = 92.6% |
This defies a widely held assumption: “building AI Agents = writing code.” But I have to say, at least at the Agent Team level, the core work of building is defining specs, not implementing features,[2] because an Agent’s behavior is determined by its Context[9] (this is the central thesis of Context Engineering)[1]. Changing a single line in CLAUDE.md can affect Agent behavior far more than writing a hundred lines of code (though you also can’t predict how it will interpret that line — something we’ll dig into in later articles).
This also explains why HANDOFF.md was the first output, why the architecture grew from needs rather than being pre-designed — because in this paradigm, every document is a materialization of a design decision. We design the system by writing documents, not just “writing documentation.”
The Part-Time Architect
There’s another set of data worth mentioning, related to time.
The activity periods over these seven days showed a clear bimodal distribution: 1 to 4 PM, and 11 PM to 2 AM. The Agent Team building happened entirely in the afternoon and late at night. This reveals a non-obvious but important characteristic: an Agent Team must be able to withstand an intermittent work rhythm. I wasn’t sitting at the computer for seven straight days building non-stop. I spent a few hours each day pushing things forward, then went to sleep, and picked up again the next day. Every time I “picked up again,” I was facing a pile of sessions in different states — some finished, some half-done, some waiting for another Agent’s output to continue.
This is precisely why state files and the HANDOFF mechanism exist. It’s also why GM’s design eventually evolved into “artifact-based progress assessment” rather than “memory-based conversation continuation” — not relying on remembering the last conversation’s content to determine what to do now, but relying on actual outputs in the filesystem (which files exist, which progress has been pushed to Git, which state records have been updated) to assess current status.
The record of 16 parallel work sessions also corroborates this — involving 17 sessions and 59 messages, indicating I frequently had multiple Agents working on different things simultaneously, then converged their outputs at some point[5]. This wasn’t a pre-designed workflow — it was a habit that naturally developed from one person pushing multiple things at the same time.
A Scene: The First Time Parallel Processing Worked
Of all the moments during the building process, one scene is particularly worth recording, because it was the first time the Agent Team truly operated “like a team.”
That day I had three Plugins packaged from external repos, and I needed to do two things simultaneously: have Em extract knowledge and methodology from these Plugins and store it in the wiki, and have C7 register these Plugins into the asset catalog. These two tasks were completely independent — Em cared about “what patterns in these Plugins are worth learning,” while C7 cared about “how to fill in the metadata, whether the contract is compliant” — so I told the Agent (at the time I was still playing the GM role myself) “give them both to me, I’ll process them in parallel.”
After the two Agents each finished, C7’s catalog went from 0 Plugins to 3, Em’s wiki went from 28 concepts to 32, with 1 new source and 1 new entity added. Each Agent’s output was thorough.
But then I asked myself a question: what did Em and C7 produce? How do they report back to GM? The answer was — there was no reporting mechanism! The two Agents each completed their work, but GM had no idea what they’d done unless I proactively read their outputs. Em updated wiki concepts, C7 registered new plugin metadata, but the connection between these two outputs (for example, Em discovering a new multi-phase-llm-pipeline pattern, and that pattern happening to be implemented by one of the Plugins C7 just registered) — nobody was making that connection.
This is exactly why the Completion Reporting Protocol was designed later. It’s also one of GM’s core responsibilities — not just dispatching tasks, but ensuring that “independently completed work” produces “meaning greater than the sum of its parts.” But in that moment, I was the one doing it. After reading both sides’ outputs, I manually cross-referenced them in my head, then recorded the insight, telling the next session “here’s how these two Agents’ outputs are connected.” That was the moment I realized that an Agent Team’s GM isn’t just a dispatcher — it needs even more to be a sense-maker, piecing together fragments scattered across different Agents’ outputs into a complete picture and becoming the Agent’s real decision-maker.
Not Automation — Structuralization
Back to that 2 AM scene at the beginning. If you ask me “after building the Agent Team, did you solve the Context hauling problem?” — honestly, not completely (claiming it’s fully solved would be lying — there’s only so much you can do in seven days). But the nature of the problem changed.
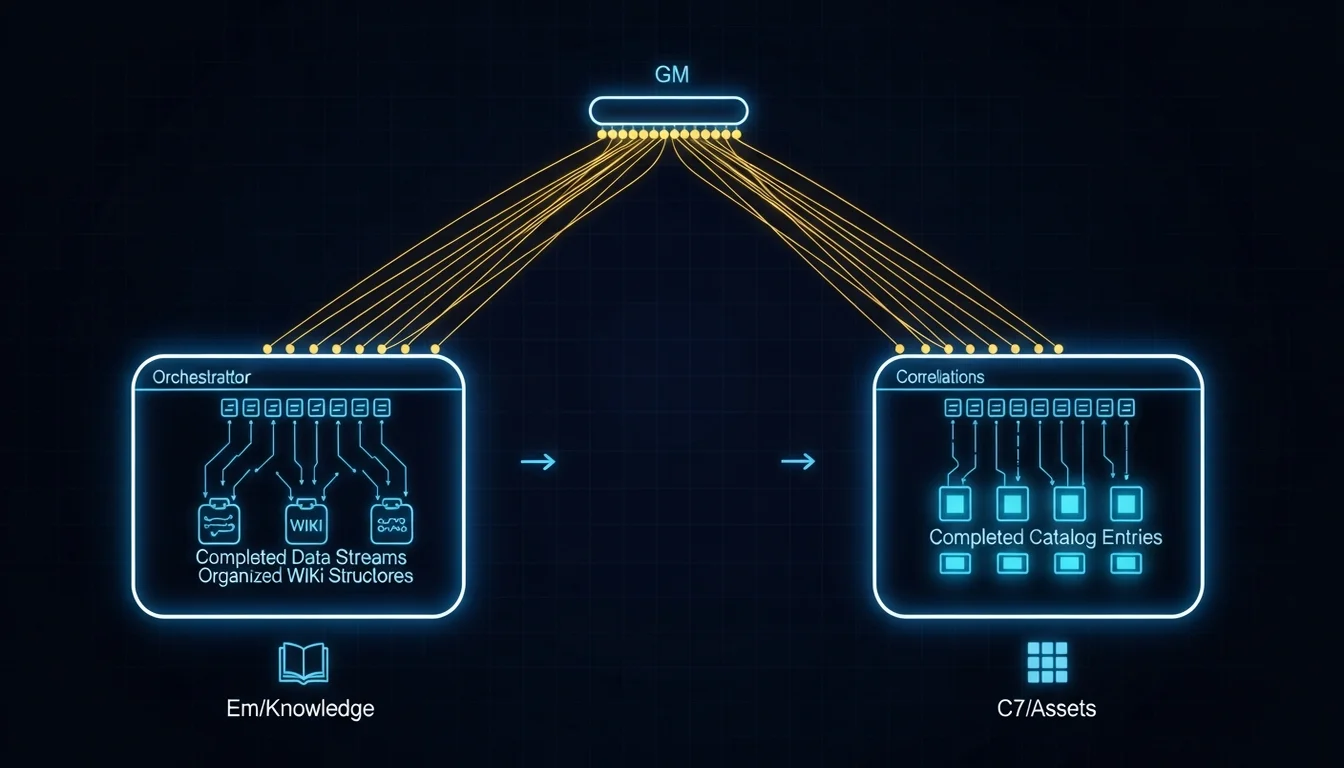
Before, I was hauling Context because “there was no proper mechanism for exchange.” Each session was an isolated island with no communication — Context could only live in conversation history, vanishing when the session ended. I needed to preserve those Contexts from a god’s-eye view using various workarounds. Now Context has structured storage locations: knowledge lives in Em’s wiki, assets live in C7’s catalog, state lives in state files, decision context lives in HANDOFF documents. All that’s left for me to figure out is the communication mechanism.
Before, I played the role of “translator” between different sessions — translating A’s output into language B could understand, then translating B’s feedback back into A’s context. Now each Agent has its own identity and professional vocabulary. Em thinks in wiki terms, C7 thinks in catalog terms. They don’t need me to translate — they just need me to point out “this concept from Em relates to this asset from C7.”
Before, I made coordination decisions based on “I think I remember we discussed this before…” — that kind of fuzzy memory. Now, when discussing design issues with an Agent, I say “first consult the methodology and knowledge in Em’s wiki, think it through, then answer me” — having the Agent find evidence from a structured knowledge base rather than guessing from its own Context.
So what the Agent Team solved wasn’t an “automation” problem — it was a “structuralization” problem. It transformed implicit knowledge that was previously scattered across my brain and various session conversation histories into information sitting on the filesystem, readable by any Agent at any point in time.
Closing Thoughts
Seven days. 31 sessions. 800 pages of a book.
If I had to sum up this starting point in one line, it would be this: Not that Subagents aren’t enough — it’s that you’ve accumulated so much Context that the cost of rebuilding it each time exceeds the cost of maintaining a persistent architecture. And when that tipping point arrives, you’ll know — because you’ll find that the time you spend “getting the AI to understand the current situation” already exceeds the time you spend “getting the AI to do actual work.”
As for what happened after this architecture was built, what consequences each design decision brought, what pitfalls were hit, some of which I still haven’t climbed out of… those are the stories for the articles ahead.
Perhaps the most counterintuitive thing about building an Agent Team is that you think you’re building a system for “getting AI to do more things for you,” but what you’re actually building is a framework for “getting what’s in your head written down” — and what gets written down happens to also be the Context that Agents need. That’s also why 97% of the first-stage output was Markdown, not Code.
References
[1] Anthropic — Effective Context Engineering for AI Agents https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
[2] GitHub Blog — Spec-Driven Development: Using Markdown as a Programming Language https://github.blog/ai-and-ml/generative-ai/spec-driven-development-using-markdown-as-a-programming-language-when-building-with-ai/
[3] WSO2 — Introducing Agent-Flavored Markdown (AFM) https://wso2.com/library/blogs/introducing-agent-flavored-markdown/
[5] Addy Osmani — The Code Agent Orchestra: What Makes Multi-Agent Coding Work (data on 40-50% coordination overhead in multi-agent setups) https://addyosmani.com/blog/code-agent-orchestra/
[9] Materialize — AI Context Engines: The Next Evolution of Context Engineering https://materialize.com/blog/ai-context-engines-context-engineering-evolution/
Support This Series
If these articles have been helpful, consider buying me a coffee