
心法一:從工具到工作流程的演進之路
前七篇我們拆解了 AI Agent 系統的技術底層:
- Model ≠ Runtime
- 五層架構:Command → Agent → Tool + Skill → Context
- Context Engineering:JIT、Token 預算、Progressive Disclosure
- Skill 生態系競爭
- Skill vs Subagent:Context 流向決定一切
- 組合模式:探索 → 決策 → 執行
- Agent Team:隔離的思考,連通的溝通,共享的狀態
這些是 背景知識,是地基,你不需要完全理解每一個技術細節,你甚至可以把這七篇文章交給 AI,直接讓它作為工作原則來遵循,然後開始實作,雖然這樣說,但你需要理解裡面的概念,這樣當 AI 出問題時,你才知道該調整什麼跟怎麼拆分。
有了前七篇的技術/武功招式,現在該是把 Mindset,也就是心法,跟大家說明的時候,從這篇開始,我們談的不再是技術或原理,而是 心法 畢竟學完了招式,要有心法支撐,才能把這些技術化為實際的工作方式。
但要注意,心法不是一成不變的原則,而是一個演進的方向。它告訴你的是:怎麼產生工作流程、怎麼形成工作的閉環,然後在這個閉環中不斷進化。
第零階段:先把工作拆分成元件,然後 AI 化
我想這階段大家已經經歷過,尤其是使用 AI 一陣子的你,我就先架設大家都碰過 AI 了,只說這一段的重點,在進入工作流程之前,你得先有「元件」,所謂元件,就是你日常工作中那些可以被獨立描述、獨立完成的任務單元。寫一段程式是一個元件,整理一份會議紀錄是一個元件,產一份報表也是一個元件。
這個階段要做的事很直覺:把你的工作拆開,然後逐一嘗試用 AI 來完成。 有些任務 AI 一次就做得很好,有些需要你調整 prompt,有些你會發現目前的 AI 還做不到,這些都是正常的,重點不是「每件事都要 AI 化」,而是透過這個過程,你會開始理解 AI 擅長什麼、不擅長什麼,以及你要怎麼描述一件事情,AI 才能正確理解你的意圖。這個「描述能力」本身,就是後面所有階段的基礎。
當你手上有了一堆可以獨立運作的 AI 元件之後,下一個問題自然就來了,這些元件之間怎麼串起來?
第一階段:從 A、B、C 到 A→B→C
現在你手上有了 A(寫程式)、B(寫測試)、C(寫文件)這些獨立的 AI 元件,各自都跑得不錯。但你每次還是要自己決定:A 做完之後,接下來該跑 B 還是 C?中間要不要先看一下改了哪些檔案?測試結果出來後要不要回頭更新文件?
這些「看一下 → 決定 → 拿結果」的動作,就是元件之間的 膠水 — 而現在這些膠水還是你在塗。
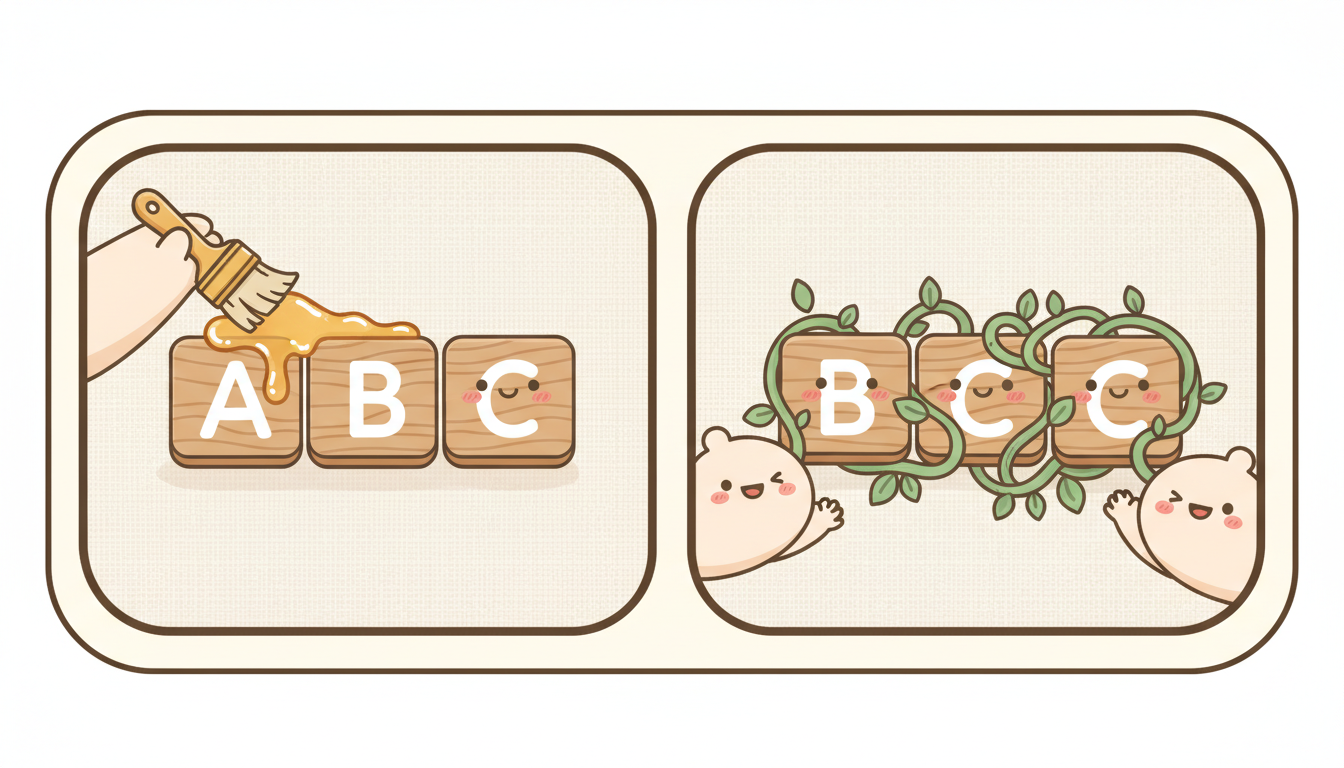
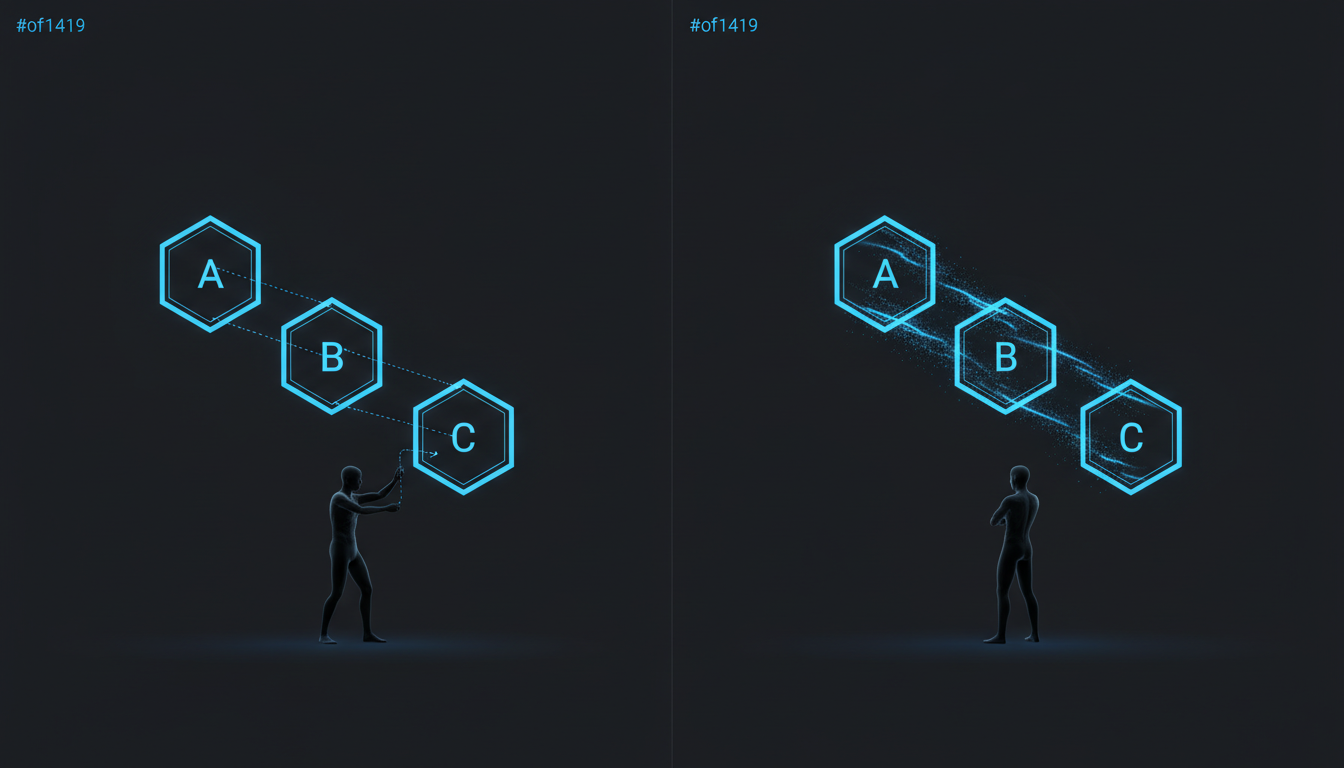
這個階段的重點,就是把膠水也交給 AI。
這不是什麼大工程。你可能只是在 Skill 裡加一段指示:「寫完程式後,自動檢查變更的檔案,判斷需要新增或修改哪些測試」。或者在 CLAUDE.md 裡加一條規則:「commit 前必須確認文件與程式碼同步」。
在這個過程中,你原本建立的 Agent、Skill、甚至 Rules,會不停地拆解又合併,不斷進化。它們會從原本各自處理 A、B、C 的三個獨立模組,變成可以處理 A+B+C 的連貫工作流程。而且這個工作流程會開始有自己的判斷 — 依照狀況自動決定是 A→C→B、A→B→C,或者只跑 B 和 C。
Anthropic 的 2026 年 Agentic Coding 報告 [10] 印證了這個起步策略:開發者約 60% 的工作已在使用 AI,但僅 0-20% 的任務可以完全委派給 AI Agent。
工程師傾向先委派「容易驗證正確性」或低風險的任務,然後逐步擴展。先把膠水交給 AI,就是這個漸進委派的第一步。
第二階段:設計 Context 的交接
當你把工作流程串起來之後,下一個問題馬上浮現:
AI 跟 AI 之間交接的時候,需要什麼 Context 才能繼續工作?
這就回到前七篇文章的核心 — Sub-agent、Skill、Context 流向。
如果你的工作流程是「調查 → 設計 → 執行」,那調查階段的 Agent 做完之後,他的發現要怎麼傳給設計階段的 Agent?哪些是關鍵資訊必須保留?哪些是中間過程可以丟棄?
這就是第三篇講的 Subagent Return Contract:探索深入,回傳淺層。第六篇的組合模式也是在處理同一個問題。Google Developers Blog 在一篇關於 context-aware multi-agent framework 的文章 [22] 中也指出,context handoff 是多 agent 架構中最核心的設計決策 — 你需要明確控制每次交接傳遞多少上下文(full vs. none 模式),這跟我們第三篇講的 Subagent Return Contract 完全一致。
但這裡有一個很容易被忽略的陷阱 — 我稱它為 Context 盲區。
陷阱:Agent 的 Context 盲區
Agent 有一個習慣:他會把自己 Context 中已知的資訊當作預設,然後在輸出中省略掉。

這在對話中通常不是問題 — 因為你跟他共享同一個 Context,你也知道那些資訊。但當他在寫文件、做交接、或產出設計文件時,問題就來了。
舉個例子:你請 Agent 把參考文件記錄下來,他會幫你製作索引,但不一定會連結到原始檔案的實際位置。因為在他的 Context 裡,他「知道」那些檔案在哪,所以覺得不需要寫出來。
但當 Session 結束後呢?當另一個 Agent 接手呢?那些「已知」的資訊就消失了。
解法很直接:在交接之前,請 Agent 自我檢查。
告訴他:「如果你現在把這份文件寫下來,有沒有任何資訊是 Session 清除之後就會消失的?有沒有任何連結、路徑、參考資料是你現在知道但沒有寫進去的?都請補上。」
這個步驟看起來微小,但它能避免大量的交接斷裂。
下一篇,我們談工作流程建立之後最關鍵的階段 — 精煉循環。迭代改進聽起來很美好,但它其實是一把雙面刃。
參考資料:
[10] Anthropic, “2026 Agentic Coding Trends Report” — 60% 工作使用 AI,0-20% 可完全委派 https://resources.anthropic.com/2026-agentic-coding-trends-report
[22] Google Developers Blog, “Context-Aware Multi-Agent Framework” — context handoff 是多 agent 架構中最核心的設計決策 https://developers.googleblog.com/architecting-efficient-context-aware-multi-agent-framework-for-production/
支持這個系列
如果這系列文章對你有幫助,考慮請我喝杯咖啡
請我喝杯咖啡
