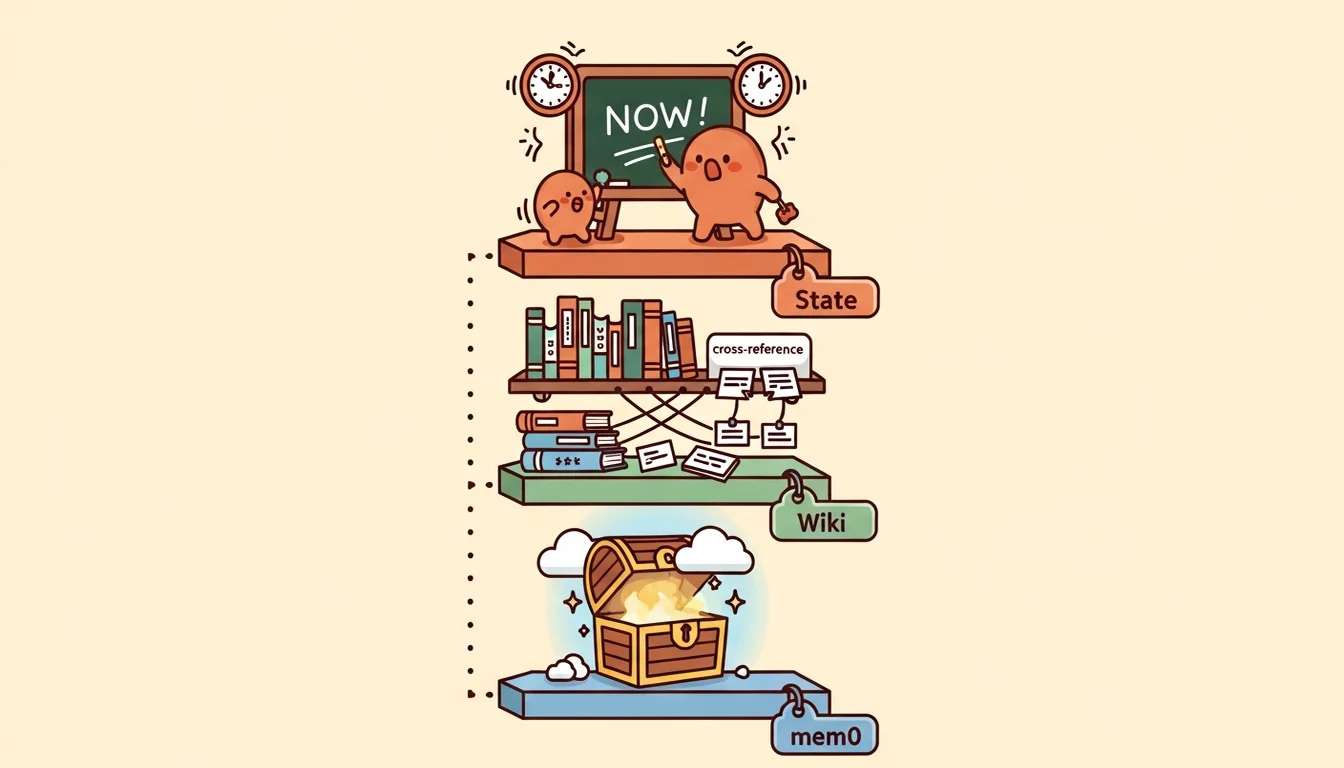

一句話: Agent Team 的記憶不是一個系統,是三個不同用途的系統疊在一起。
前一篇說到 Agent Em 的知識系統,我們接著說跟知識系統有關的記憶系統。
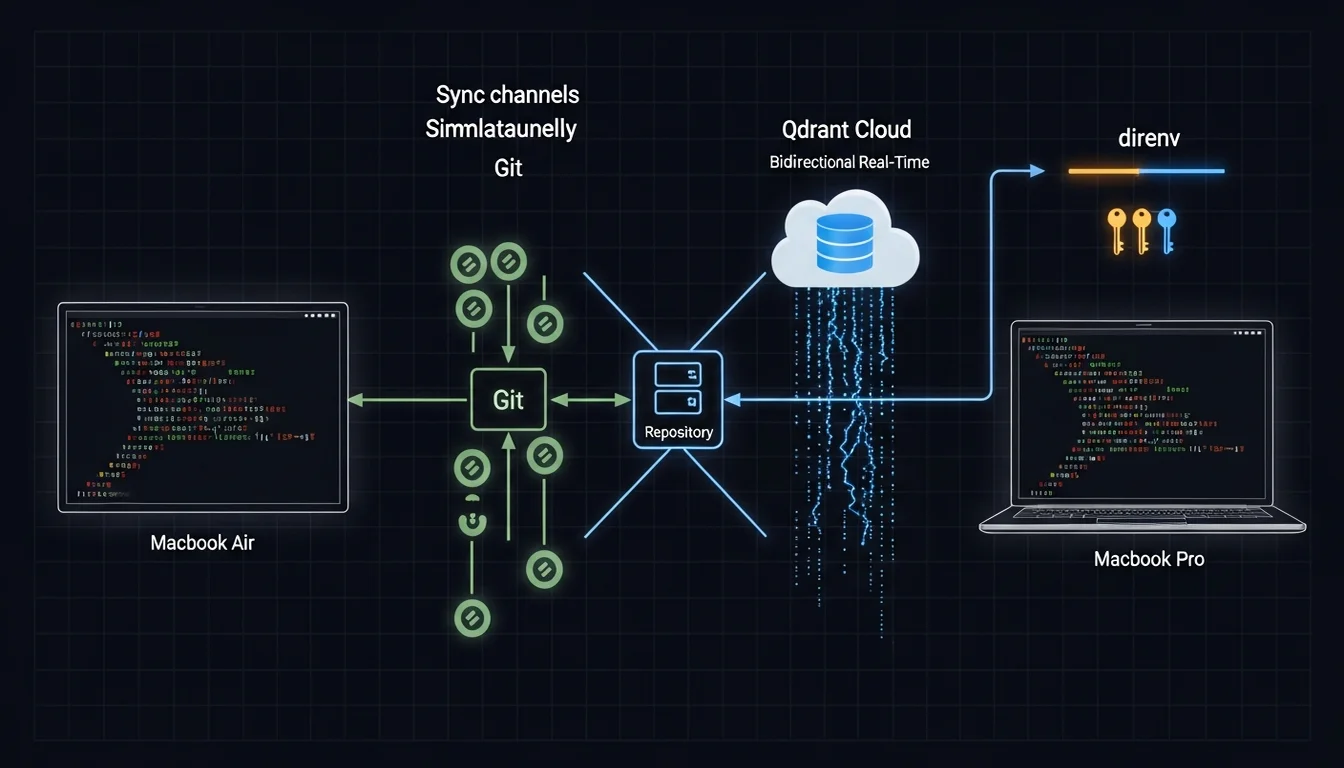
我在專門帶出門的 Macbook Air 上跟 GM 討論了一個設計決策,具體是關於 Em 和 C7 在做平行處理的時候,完成報告的格式應該包含哪些欄位、用什麼結構回報給 GM,討論了十幾分鐘,做了幾個判斷,結束 session。
隔天我打開我桌上的老 Macbook Pro,啟動 GM,問他「我們之前決定 completion report 的格式是什麼?」,他不知道,其實這是一個很常見的場景,因為他根本不記得有這段對話,那段對話發生在我帶出門的 Macbook Air 上,所以這段對話的 session 歷史儲存在那台機器的 ~/.claude/ 裡,換一台機器當然會「失憶」。
這揭露了一個我們需要接著要思考的問題:Agent 的記憶問題不是「能不能記住?」,而是「在哪裡記住?」。 Context window 夠大、session 歷史可以 resume,這些都是「單台機器、單一 session」標準工作流程,但當你的工作跨越多台機器、多個 session、多個 Agent 的時候,「記住」這件事突然變成了一個分散式系統的問題,甚至你要創建一個給多人使用線上系統,怎麼管理每個人的 Repo, Agent, Memory,頓時成了一個 IT 級別的分散式記憶管理問題。
三層記憶:State、Wiki、mem0
萬事起頭難,經過了 Agent Em 的常識,我知道這次我要更小心,所以我設計了一個三層的記憶架構 [2] [10],不是因為我喜歡把東西分成三層(前面好像一直用到 3 這個數字?),而是因為我在實際跟 Agent 協作中碰到的三種需要 Agent「記住」的需求場景,他們在性質上完全不同,如果塞在同一個系統裡會互相干擾(不過也有研究者認為,動態自組織記憶可能比靜態分層更有適應性 [3],不過用 AI 就是這樣,今天的黃金定律或許明天就被推翻,先動手做反而可以學到更多),所以我把這三種需求場景定義如下:
State(正在做什麼): 最不穩定的層,更新頻率以分鐘計,內容是「目前誰在做什麼、做到哪裡了、下一步是什麼」。存在 agent-GM/state/team-status.md,GM 每次開 session 都會讀,做完事就更新,走 Git 同步,所以跨機器可見。
Wiki(我們知道什麼): 中等穩定,更新頻率以天計,內容是 Em 編譯過的結構化知識,concept 頁面、entity 頁面、交叉引用、分析報告(上一篇講了很多)。存在 agent-Em/wiki/,走 Git 同步。任何 Agent 都可以讀,但只有 Em 可以寫。
mem0(為什麼做這個決定): 最穩定的層 [1],更新頻率以週計,內容是跨 session 的決策記憶,比如「我們決定 GM 管內部狀態、G7 管外部 fleet」「Em refactor 的原因是 CLAUDE.md 違反了 wiki 裡的方法論」這種判斷和理由。存在 Qdrant Cloud [4],走雲端同步,跨機器即時可見。
為什麼不能合併成一個系統? 因為三層的更新頻率、查詢模式、擁有者都不一樣。State 每幾分鐘就變一次,你不會想把它丟進 wiki(wiki 的 /ingest 流程太重,不適合高頻更新),Wiki 的內容需要結構化的交叉引用,你不會想把它丟進 mem0(mem0 是向量搜尋,不是結構化文件),mem0 的內容需要跨機器即時同步,你不會想把它丟進 Git(Git 需要手動 commit + push,不是即時的)。
| 層次 | 內容 | 更新頻率 | 同步方式 | 擁有者 |
|---|---|---|---|---|
| State | 目前在做什麼 | 分鐘級 | Git | GM |
| Wiki | 我們知道什麼 | 天級 | Git | Em |
| mem0 | 為什麼這樣決定 | 週級 | Qdrant Cloud | GM(Phase A) |
mem0 遷移:從 Chroma 到 Qdrant Cloud
mem0 最早是跑在本機的 Chroma(一個本地向量資料庫)上面 [5] [6],Phase A 只給 GM 用,用法很簡單:session 開始的時候用 SessionStart hook 自動搜尋相關記憶,session 結束前用 /m0-add 手動存入新的決策記憶(後期為了「做夢」讓他自動化了)。
但「本機」就是問題。一台 Mac 上存的記憶,另一台 Mac 看不到,而我在多台機器甚至雲端、手機之間切換工作是常態。
決定遷移到 Qdrant Cloud 的過程本身不複雜(建一個 free tier cluster,改一下 config 裡的 vector store 設定),但遷移路上碰到了幾個坑。
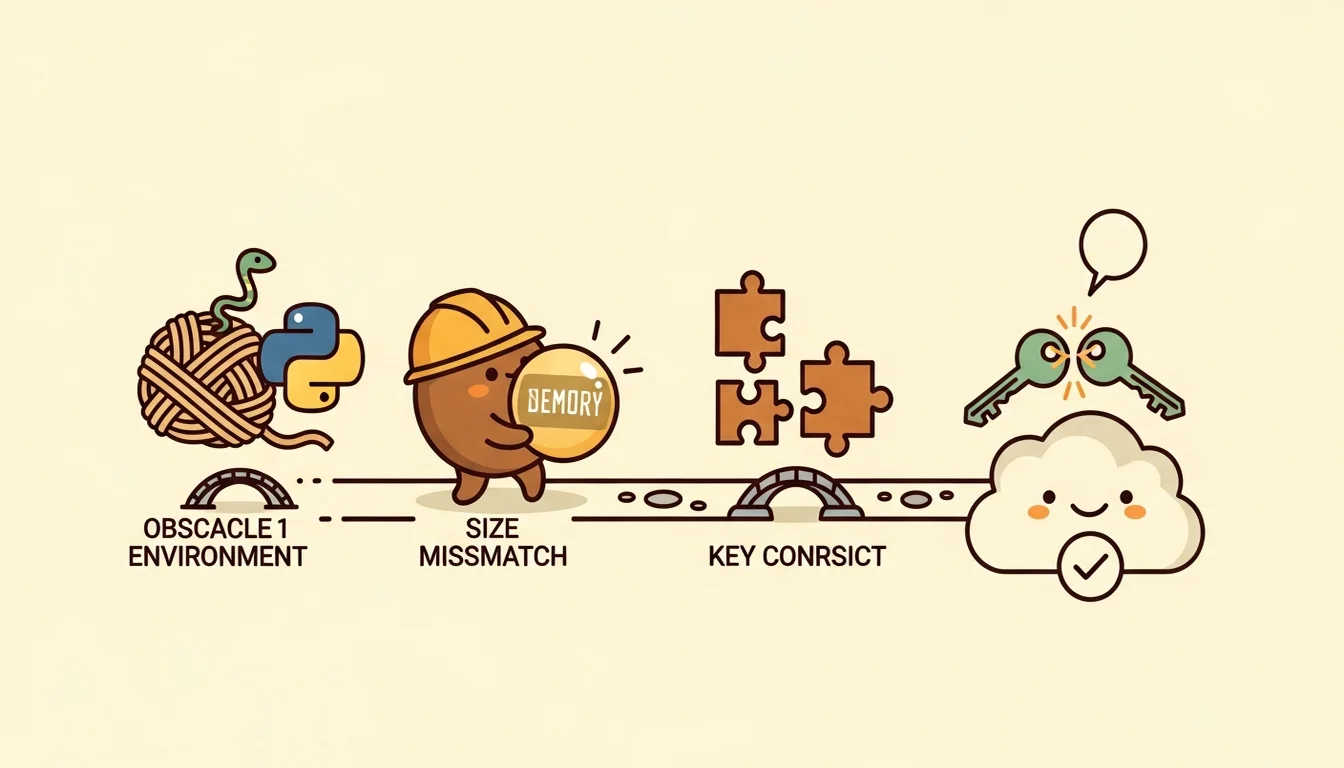
第一個坑是 macOS 的 Python 安裝限制, 新版 macOS 的 Python 禁止直接安裝第三方套件,理由是防止使用者破壞系統的依賴環境,這意味著 mem0 需要的那些 Python 套件不能直接裝,你必須先建一個隔離的 Python 環境,把套件裝在裡面。
還好我之前已經有 venv,但接下來碰到了一個連鎖問題:我用環境變數管理工具(direnv)在進入 repo 目錄時自動啟用這個隔離環境,但 Claude Code 的 SessionStart hook 在執行的時候,走的是另一條路徑,讀不到 direnv 的設定,所以 hook 啟動 mem0 的時候找不到正確的 Python,修正方式也不困難,讓設定檔偵測自己被誰呼叫,分別用不同的方式載入環境就好,這兩個問題問問 AI 或 Google 都可以解決。
第二個坑是向量維度對不上, 這個單純是 Default 值的問題,因為 Qdrant Cloud 在建資料庫時如果沒指定維度,他會用預設值,但我給 mem0 用的語意模型輸出維度跟預設值不一樣,第一次存記憶的時候就報錯了,384 維的向量(一開始不想搞太大)塞不進 1536 維的容器。
解法也很簡單,刪掉 Qdrant 上的資料庫,然後在 mem0 設定裡讓它重建,重建之後存入和搜尋的全 Data Chain Pass。
第三個坑是 API key 衝突。 mem0 需要 Anthropic 的 API key 來做語言模型的呼叫(它是獨立的 Python 程式,不走 Claude 訂閱),所以環境設定裡需要放一個 Anthropic API key,但 Claude Code 也會讀這個環境變數,如果偵測到有 key,他會優先用 key 而不是用訂閱的登入,這個我在 Claude Code 多帳號並行指南 裡頭有說過,這個問題是我在隔天才發現,因為 Claude Code 剛啟動時會出現你使用的模型跟使用方式,但通常都沒在看,通常你只會看帳單時發現有差異(又一個 silent failure),修正方式也很簡單,把環境變數改名加上 mem0 專屬前綴,讓 Claude Code 不認得它,只有 mem0 的腳本知道去讀這個名字。
三個坑的共同特性:每一個都不是 mem0 本身的問題,而是 mem0 跟它的運行環境(macOS Python、Qdrant 預設值、Claude Code 環境變數)之間的摩擦, 記憶系統的難點不在於「存」和「取」,而在於讓它在一個由多個工具組成的生態系裡穩定運作。
QMD 整合:不是第四層記憶,是搜尋介面
上一篇末尾提到,Em 的 wiki 越來越大之後,每次 /query 的 token 成本線性增長,因為 Em 缺少一個搜尋層,QMD 就是用來解決這個問題的。
QMD 是一個本地的搜尋引擎,專為 markdown 文件設計,有三種搜尋模式:關鍵字搜尋(最快)、語意搜尋(理解同義詞和自然語言)、以及混合模式(最慢但最準,會自動把你的問題展開成多個變體去搜)。
QMD 不是第四層記憶 [9], 他不存任何新的知識,他只是 wiki 的搜尋介面,wiki 頁面還是 Em 寫的 markdown,QMD 只是把這些 markdown 做了 index,讓查詢的時候不需要遍歷整個 wiki。
整合分成三個階段,每個階段一個乾淨的 commit:
Phase 1(Em 內部改造): 修改 Em 的查詢流程,從「讀索引 → 猜哪些頁面相關 → 全部讀取」改成「先搜尋 → 只讀搜尋結果回傳的頁面」,同時在 ingest 流程結尾加了一步自動更新搜尋索引,讓每次新增知識之後搜尋都能找到,升級完之後,查詢的 token 成本從「跟 wiki 大小成正比」降到「跟相關頁面數成正比」。
測試的時候還碰到了一個有趣的現象:我用一個完全不存在的 topic 做測試,搜尋引擎還是回了高分結果,因為他太努力找匹配了,把不存在的這個關鍵字展開成「未定義的變數」,然後匹配到了一個講 Context 盲區的頁面,不過實務上 Agent 不會查亂碼,真正的 knowledge gap 案例會表現得更合理。
Phase 2(開放給其他 Agent): 在 C7 的 catalog 裡建立 QMD 的工具規格和一個 wiki 搜尋 skill,讓其他 Agent(比如 Dm 在設計新 Agent 時需要查知識)可以不用經過 Em,直接搜尋 wiki。這是一條「輕量級的知識存取路徑」,不需要啟動 Em 就能拿到結果。
Phase 3(更新架構文件): 更新 Em wiki 裡的記憶架構頁面,把 QMD 作為搜尋介面加進去,同時建了一份分析頁面記錄整個整合的設計決策和取捨。
三個階段的邏輯是刻意設計的:先改 Em 內部的 query 機制(Phase 1,最小風險,只影響 Em 自己),確認 search-first 的模式可行之後,才把搜尋能力開放給其他 Agent(Phase 2),最後才更新架構文件(Phase 3,因為你不想在機制還沒穩定的時候就把它寫進 source of truth)。
順序很重要:為什麼先 QMD 再 mem0 Phase B
有一個不明顯但重要的設計決策:為什麼先做 QMD 整合,再做 mem0 的 Phase B(把 mem0 從 GM-only 擴展到所有 Layer 2 agent)。
原因是 Em 的知識模式要先穩定,才能定義 mem0 的 extraction rules。
mem0 Phase B 的核心挑戰不是技術(技術上就是在其他 Agent 的 session hook 裡加 mem0 呼叫),而是「每個 Agent 應該記住什麼」,比如 Em 記住的是知識結構的演變(wiki concept 的新增和修改),C7 記住的是資產管理的決策(為什麼某個 skill 被接受或拒絕),Dm 記住的是設計經驗(某個 Agent 的設計選擇成功或失敗的原因)。
但要定義這些 extraction rules,你需要先理解每個 Agent 實際在做什麼,而理解他們在做什麼的前提是 Em 的知識庫穩定且可查詢,如果 Em 的 wiki 還在用 eager loading 的方式查詢(每次都讀所有頁面),那其他 Agent 在設計 extraction rules 的時候就沒辦法快速驗證「這條記憶有沒有跟 wiki 裡的既有知識重複」。
而在 QMD 整合完成之後,Em 有了 search-first 的 query 能力,其他 Agent 也可以直接用 QMD 搜尋 wiki,這讓 mem0 Phase B 的 extraction rules 設計有了可靠的「知識去重複」機制:在存新記憶之前,先搜尋 wiki 確認這個知識是不是已經被 Em 結構化地記錄過了。
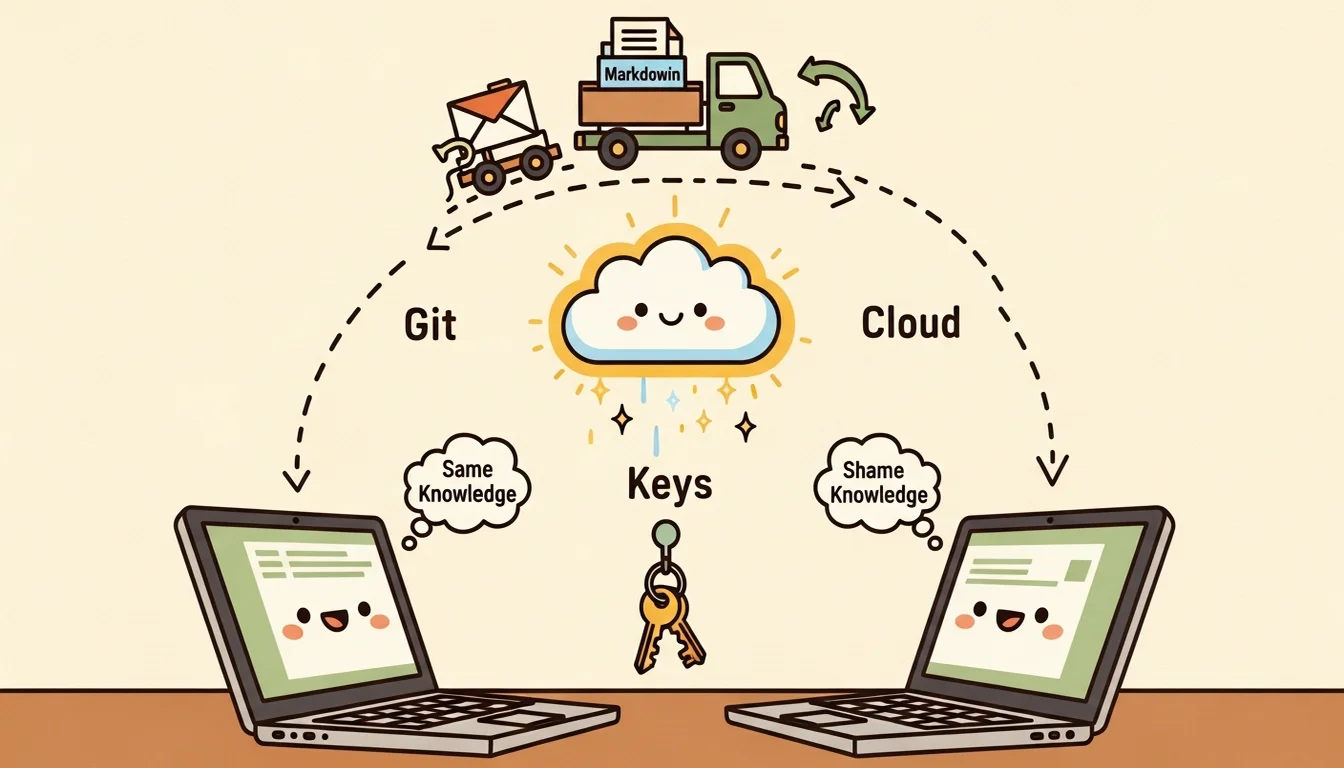
跨機器同步的完整解法
回到開頭那個場景:我在出門用的 Macbook Air 上做了決策,隔天在當成桌機使用的另一台老 Macbook Pro 上問 GM,他不知道。
三層記憶架構解決了這個問題,但每一層的同步方式不一樣:
Git(State + Wiki): 在一台機器上更新 team-status.md 或 Em wiki 之後,commit + push,另一台機器 pull 就能看到 [7],這不是即時的(需要手動 git 操作),但 State 和 Wiki 的更新頻率夠低(分鐘級到天級),手動同步可以接受。
Qdrant Cloud(mem0): 在一台機器上用 /m0-add 存入記憶,另一台機器的 SessionStart hook 立刻就能搜尋到,因為 Qdrant Cloud 是雲端服務,不需要任何同步操作。
direnv(環境變數): .envrc 檔案透過我建立的雲端機制交換(NAS 很適合放這種輕量服務,用 AI 開發也快),同步之後 direnv allow 就能載入,API key、venv 路徑、環境設定都在裡面。
三個同步機制各自負責一個層次,沒有重疊,也沒有遺漏 [8],State 和 Wiki 用 Git 是因為它們是結構化的 markdown 檔案,Git 的 diff 和 merge 很適合,mem0 用 Qdrant Cloud 是因為決策記憶需要即時可見,不應該等 Git 操作,環境變數用 direnv 是因為它需要在進入目錄的時候自動載入,不應該手動 export。
(你可能會覺得「三個不同的同步機制」聽起來很複雜,但比起把所有東西塞進一個系統然後發現某些場景它處理不了,三個各自負責自己擅長的事情,反而更簡單,至少在 debug 的時候一出問題你就知道該看哪裡。)
記憶不是一個問題
回頭看整篇的脈絡,你會發現我在建構 Agent Team 記憶系統的過程中強調的最重要的一件事是:「Context 持久化」不是一個問題,而是一組不同層次的問題。
「正在做什麼」的持久化(State)、「我們知道什麼」的持久化(Wiki)、「為什麼這樣決定」的持久化(mem0),這三個問題的性質完全不同,需要的解法也完全不同,如果你試圖用一個系統解決所有問題(比如全部塞進 Context window,或者全部存進向量資料庫),你會發現某些場景下它工作得很好,某些場景下它完全不適用,然後你開始上 Patch,補到最後你其實已經隱性地建了三個向性的系統,只是沒有明確區分,這樣反而不如一開始就先把地基長好,之後更好處理。
之前在寫 Context Engineering 那篇的時候,我提過 JIT loading 的原則,那個原則在記憶系統這裡有了更具體的意義:不只是「需要的時候才載入」,而是從「正確的層載入正確類型的知識」, State 問的是「現在」,Wiki 問的是「什麼」,mem0 問的是「為什麼」,三個問題導向三個不同的資料源,混在一起在某些情況下會讓查詢變慢、結果變雜。
或許,記憶系統最反直覺的設計原則是:不要試圖讓 Agent「記住一切」,而是設計一套機制,讓他在需要的時候能「找到」對的東西。 記住和找到是兩回事,記住是把東西塞進 Context、Rules、Memory,找到是知道該去哪裡問。
或許,這也是為什麼我的記憶系統裡最晚才穩定的不是存入機制,而是搜尋機制(QMD),因為存東西很容易,找到對的東西才是真正的挑戰。
參考資料
[1] arXiv — Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory https://arxiv.org/abs/2504.19413
[2] arXiv — Multi-Layered Memory Architectures for LLM Agents: An Experimental Evaluation(多層記憶:working memory、episodic、semantic、procedural) https://arxiv.org/html/2603.29194
[3] arXiv — A-MEM: Agentic Memory for LLM Agents(NeurIPS 2025,反面觀點:動態自組織記憶可能比靜態分層更有適應性) https://arxiv.org/abs/2502.12110
[4] Qdrant — Mem0 + Qdrant Integration Documentation https://qdrant.tech/documentation/frameworks/mem0/
[5] Airbyte — Chroma DB vs Qdrant: Key Differences https://airbyte.com/data-engineering-resources/chroma-db-vs-qdrant
[6] 4xxi — Vector Database Comparison 2026(注意:ChromaDB 2025 Rust 改寫後效能提升 4x,差距可能已縮小) https://4xxi.com/articles/vector-database-comparison/
[7] DEV Community — How I Gave My AI Agents a Permanent Memory That Syncs Across Machines(git-synced MCP memory server 實作) https://dev.to/keshrath/how-i-gave-my-ai-agents-a-permanent-memory-that-syncs-across-machines-4755
[8] DEV Community — Designing Memory for 20 AI Agents Across 9 Nodes(跨機器同步的 race condition 問題) https://dev.to/linou518/designing-memory-for-20-ai-agents-across-9-nodes-multi-agent-memory-architecture-4nhe
[9] Martin Fowler — Strangler Fig Pattern(支持「先建搜尋介面再完成遷移」的漸進式架構策略) https://martinfowler.com/bliki/StranglerFigApplication.html
[10] Analytics Vidhya — Architecture and Orchestration of Memory Systems in AI Agents https://www.analyticsvidhya.com/blog/2026/04/memory-systems-in-ai-agents/
支持這個系列
如果這系列文章對你有幫助,考慮請我喝杯咖啡
請我喝杯咖啡
