
一句話: Agent 溝通的底層是 OS IPC,但 OS 假設所有 process 長一樣,而我的每個 Agent 都不一樣。
在建構 Agent Team 的過程中,我很早就有一個感覺:Agent 之間的溝通問題好像在哪裡見過。
去年 11 月我的 Agent 架構迭代到第四次的時候我想起來,這些架構、問題其實在作業系統的框架裡都有,Process 之間怎麼傳遞資料?IPC,Inter-Process Communication,pipe、shared memory、message queue、file lock,這些概念在大學接觸作業系統框架的時候都學過(雖然那時候不覺得有一天會用來設計 AI Agent 的溝通架構)。
於是我回頭翻了資料,理解了 OS 的框架,但是沒有照搬 OS 的做法,因為我還是看到了些 Gap,概念通了,但是落地還要是自己想辦法,所以我決定從實作中一步步長出了我自己的設計可能會更好,所以從 dispatch 的兩條路(第五篇)、三種混合模式(Mode A / B / C)、到 hook chain、inbox/outbox 的這些設計,都不是從書裡可以推導出來的,而是從「Em 被 spawn 出來不知道自己是 Em」「GM 一直忘了 cd」「hook 格式錯了但沒有報錯」這些實際遇上的挫折跟失敗裡頭挖掘出來的,所以後來我忘了他。
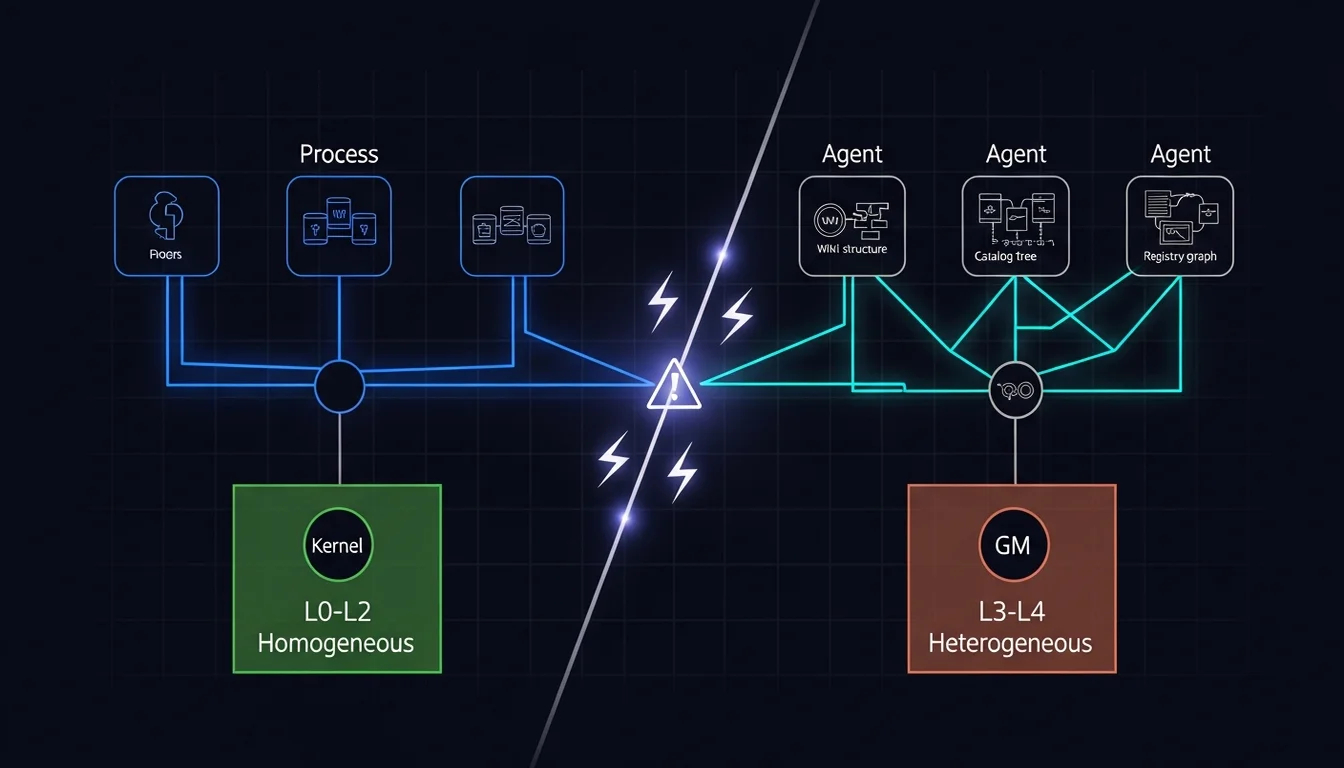
兩週前我同事重新提了這個想法,而且更細緻,所以我寫了一篇番外篇從他的觀點來看這件事,但跟幾個月前不同,這次我有了 Agent Team,所以我請 Em ingest 了 OS 框架(就是上一篇番外裡介紹的那個五層決策模型),我想看看跟過這幾個月,我是否還是走在這條路上?結果我發現底層的選擇(L0-L2)我已經做對了,跟框架對齊了,但上層(L3-L4)還是有一些 OS 框架解決不了的問題,因為 OS 假設所有 process 是同構的,而我的 Agent Team 裡每個 Agent 都是異構的。
L0-L2:OS 框架完全適用
回頭看看番外篇裡的五層決策模型(L0 Environment → L1 Transport → L2 Topology → L3 Protocol → L4 Content Contract),有些有趣的東西,但如果你跳過了番外篇,那讓我在這裡先快速帶過我的 Agent Team 在底層三層的定位跟對應的 OS 框架:
- L0 = Same machine(所有 Agent 都是同一台 Mac 上的 Claude Code session)
- L1 = File I/O(inbox/outbox 目錄 + pipe 用於 subagent,file 是 same machine 下最好 debug 的 transport,
cat inbox/就能看通訊內容) - L2 = Star(GM) + limited peer(GM 做中央協調,Agent 之間可以透過 filesystem 直接溝通做核心工作)
這三層的選擇跟 OS 的框架經驗其實相當一致,當然,當時我在做這些選擇的時候並不是有意識地在「套用 OS 模型」,而是從實際場景中推導出來的(第五篇的那些 silent failure 讓我意識到 file I/O 的 debug 優勢,混合 topology 是從 GM 成為瓶頸的經驗裡長出來的),現在回頭看,算是幫我打了定心針,確認我走的方向是對的。
但到 L3 就碰壁了:OS 的 process 長一樣,我的 Agent 不一樣
L0-L2 很整齊,OS IPC 的框架可以完美適用,但到了 L3(Protocol)和 L4(Content Contract),我發現 OS 的框架對不上了,而且原因很根本:OS 的 process 是同構的,我的 Agent 是異構的。
OS 裡的 process,不管跑什麼程式,都是在同一個 kernel 底下,使用同一套 syscall,接受同一個 scheduler 的管理,每個 process 之間的差異只在於「跑什麼程式」,但運作框架是一致的,所以從 OS 框架的觀點來看,我們可以用一個統一的 protocol 來處理 IPC,不管你是 web server 還是 database,pipe 就是 pipe,signal 就是 signal。
但在現在的 Agent Team 裡,每個 Agent 的架構、Context 結構、工作流程都不同:
Em 有自己的 wiki 結構(concepts / entities / sources / analysis 四種頁面),有 ingest / query / lint 三個 command,他的 Context 裡經常裝著 10 數個 concept 頁面的交叉引用。
Dm 有三個 subagent(Architect 用 Opus 做設計、Scaffolder 用 Sonnet 搭建、Validator 用 Sonnet 驗證),他的 Context 流動方式是 Architect 的 plan 傳給 Scaffolder,Scaffolder 的產出傳給 Validator,是一條內部 pipeline。
C7 有 catalog 索引和 provisioning 機制,他的工作是維護 shared skill 的 canonical location,然後把 skill 推送到其他 Agent。
G7 有 registry 和 fleet management,他管理的是 Layer 3 的外部 Agent,有 sacred boundary(只有他能跟 Layer 3 說話)。
這些 Agent 不是「同一個 kernel 底下跑不同程式的 process」,他們更像是「不同作業系統的程式,碰巧接在同一個網路上」,每一台機器的內部架構、檔案系統、運作邏輯都不一樣,我不能用一個統一的 protocol 來處理他們之間的溝通,因為他們「做完事之後產出的東西」長得完全不一樣。
這個異構性帶來了五個 OS 框架解決不了的問題:
問題一:Shell hook 無法提取 LLM 判斷
OS 的 process 結束時,你可以用 exit code 告訴呼叫者「成功或失敗」,可以用 stdout 把結果傳回去,這是 OS 的標準做法。
而打從一開始,我們設計的 Level 1 Completion Report 也有著一樣標準漂亮的框架,預設讓每個 Agent 結束時自動寫一份結構化的完成報告到 GM 的 inbox,包含 agent 名稱、任務描述、結果(完成 / 部分 / 失敗)、變更的檔案數,以及一個 Flag 欄位(如果發現什麼不尋常的事就寫一句話)。
就像前面說的,設計得很漂亮,但其實** Flag 欄位從未被使用過。**
原因是:Stop hook 是 shell script,它只能寫 static JSON(時間戳、agent 名稱這些固定欄位),它沒辦法提取 LLM 的判斷,「這次任務有什麼值得注意的發現?」這種需要推理的 Flag 欄位,shell script 根本填不了,而 Agent 結束 session 之後 AI 模型已經不在了,你沒辦法在 hook 裡面問他。
OS 的 process 可以在結束前把判斷寫到 stdout,但 Agent 的「判斷」存在模型的 Context 裡,hook 觸發的時候 Context 已經消失了,Agent 的結束不像 process 的結束,它是一個有狀態的思考者的消亡,不是一個無狀態的程式的終止。
問題二:Filesystem IS the result
更根本的問題是:Level 1 Report 就算能寫,也是多餘的。
OS 的 process 做完事之後,結果通常存在某個不容易直接檢視的地方(資料庫的某張表、記憶體的某個 address、或在某個二進位的檔案中),呼叫者沒辦法直接「看懂」結果,所以需要 process 寫一份描述性的報告,用 stdout 告訴你「我寫了 3 筆資料到 table X」「計算結果是 Y」,報告和結果是兩件事。
但這邊的 Agent Team 不一樣,Em 做完 ingest,新的 wiki 頁面就在 wiki/ 目錄裡,打開就是結構化的 markdown,Dm 做完 scaffold,新 Agent 的目錄結構就在那裡,CLAUDE.md 打開就是身份定義,C7 做完 provision,skill 檔案就在目標 Agent 的 .claude/skills/ 裡。每個 Agent 的產出本身就是人類和 GM 可讀的 artifact, 你不需要 Agent 再寫一份「我建了哪些頁面、改了哪些設定」的摘要,因為產出本身就是自描述的。
GM 確實需要知道「去哪裡看」(這就是後面會講的 inspection map),但他到了那裡之後,看到的就是結果本身,不是結果的描述。在 OS 裡,「報告」和「結果」是分離的(你用 stdout 描述結果,而結果本身在別的地方),但在 Agent Team 裡它們 collapse 了, Agent 寫到 filesystem 的東西就是他的產出,不需要額外的 reporting protocol 來描述這些產出。
問題三:統一格式在異構 Agent 間沒有意義
OS 可以用統一的 message format 來做 IPC,因為 process 之間的差異只在內容,不在結構。但我的 Agent Team 的產出結構天生不同:
- Em 的產出是 wiki 頁面(有 frontmatter、交叉引用、概念分類)
- Dm 的產出是目錄結構(CLAUDE.md + skills/ + commands/ + settings.json)
- C7 的產出是 catalog entry + provisioned skill 檔案
- G7 的產出是 registry entry + health state
你要怎麼用一個 unified report format 來描述這四種完全不同的東西?硬套統一格式只會逼每個 Agent 把自己的產出壓縮成一個通用的摘要,丟掉最有價值的結構化資訊。
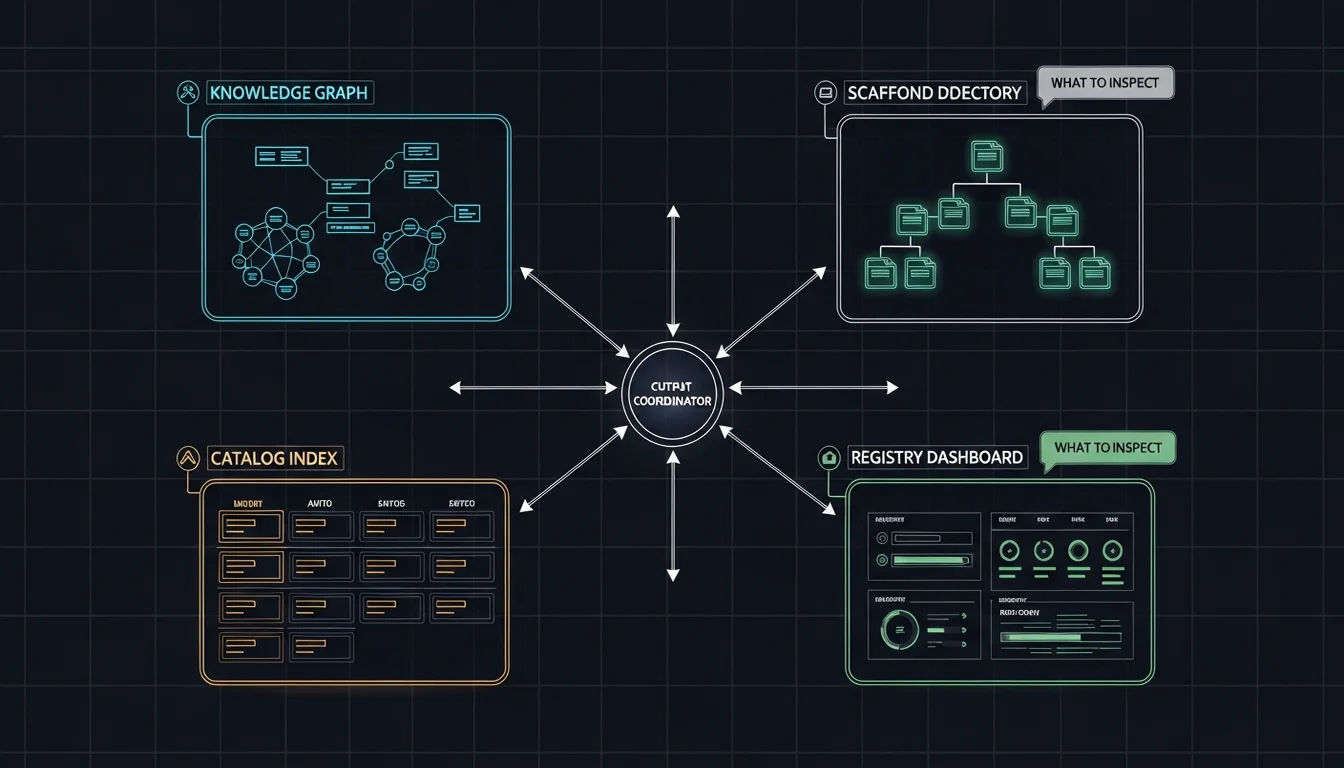
所以我最後的做法不是統一格式,而是反過來,建了一個 inspection map,讓 GM 知道每個 Agent 的產出在哪裡看、看什麼:
| Agent | 去哪看 | 看什麼 |
|---|---|---|
| Em | wiki/log.md、新建/更新的頁面 | source 正確摘要、concept 提取、交叉引用更新 |
| Dm | scaffolded 目錄、修改的 Agent 檔案 | 結構符合設計、skill 接好、品質閘門通過 |
| C7 | catalog/INDEX.md、provisioned skill 目錄 | catalog entry 完整、skill 正確推送到目標 |
| G7 | registry/agents.md、agent health state | Agent 已註冊、dispatch 驗證、健康狀態正常 |
這比 unified report format 更精確也更完整,因為 GM 去看的是 Agent 實際產出,不是 Agent 寫的摘要(而且 Agent 寫的摘要有可能遺漏或美化)。
問題四:接收方的 Context 會被降級
OS 的 process 收到 IPC 訊息,不會因為訊息太長就「變笨」。但 Agent 會。
Agent 的 Context window 是有限的,每多一個 token 都在佔用推理空間,而且 LLM 的 attention 機制意味著過多的無關 context 會降低模型對重要資訊的關注度 [1],所以 Agent 之間的溝通不只是「傳到了沒」的問題,還有「傳了之後對方能不能有效使用」的問題。
這就是為什麼五層模型的 L4(Content Contract)在 Agent 溝通裡比在 OS IPC 裡重要得多,在 OS 裡 L4 幾乎不是問題(頻寬和記憶體通常不是瓶頸),但在 Agent 裡 L4 是成敗的關鍵, 一個 Agent 如果把 raw context dump 傳給另一個 Agent,接收方的 context window 直接爆掉,推理品質斷崖式下降。
所以我在很早之前就設計了 Return Contract(explore deep, return shallow):Level 1 回報不超過 200 tokens,Level 2 不超過 2000 tokens,不管 Agent 內部處理了多少資料,回傳給 GM 的一定是壓縮過的結果,如果 GM 需要更多的訊息,就去讀取指定的檔案,這跟 Subagent 的設計原則是同一條(第五篇講的 Context 流向),只是把它延伸到了所有 Agent 之間的溝通。
Content Contract 本質上是 Context Engineering 延伸到溝通層面, 你用什麼原則管理 Agent 的 Context(JIT loading、token budgets、selective loading),就應該用同一套原則管理 Agent 之間傳遞的訊息。


問題五:身份載入是 OS 不存在的維度
OS 的 process 被 fork 出來之後,繼承 parent 的 environment,然後 exec 自己的程式,這個過程不需要「載入身份」,因為 process 不需要知道「自己是誰」就能工作。
但 Agent 需要,而且這件事在第二篇(身份)和第五篇(dispatch)都花了大量篇幅討論,Em 必須載入自己的 CLAUDE.md(裡面有他的方法論和約束)、自己的 Skills(wiki-schema)、自己的 Commands(ingest / query / lint),如果他載入了 GM 的 CLAUDE.md,他會用 GM 的判斷框架思考,做出來的結果就不對。
五層模型裡沒有「身份載入」這個維度,因為這是 Agent 特有的問題,OS 的 process 不需要「知道自己是誰」,但 Agent 的每一個判斷都受到他的身份(CLAUDE.md)影響,身份不只是 metadata,它是 Agent 的推理框架, 載入錯誤的身份不是「名字搞錯了」的問題,而是「用錯誤的邏輯做所有決策」的問題。
這也是我為什麼需要 Hybrid Dispatch(Mode A / B)的根本原因:Option A(Agent Teams)的 cwd 繼承限制讓 Agent 無法載入自己的身份,所以 Option B(CMUX split-pane)讓 Agent 在自己的目錄啟動,原生載入自己的一切,這不是效能考量也不是架構偏好,而是身份載入的需求逼出來的設計。
五個問題,五個 OS 框架沒有的答案
回頭看,五個問題各自長出了一個 OS 框架裡找不到的設計:
| 問題 | OS 的做法 | 我的做法 | 為什麼不同 |
|---|---|---|---|
| 結果提取 | exit code + stdout | Filesystem IS the result | Agent 結束時 LLM 已消亡,無法寫 stdout |
| 結果呈現 | 統一 message format | Inspection map(per-agent output domain) | 每個 Agent 的產出結構天生不同 |
| 傳輸品質 | 不影響接收方處理能力 | Return Contract(< 200 / 2000 tk) | Context window 有限,多餘 token 降低推理品質 |
| 身份 | Process 繼承 parent env | Hybrid Dispatch(Option B 讓 Agent 在自己目錄啟動) | Agent 的身份影響推理框架,不只是 metadata |
| 排程 | 統一 scheduler 管所有 process | 三種 dispatch 模式(A / B / C) + human judgment gate | 異構 Agent 不能用統一規則管 |
L0-L2 是 OS IPC 的 Domain,五層模型在這裡提供了正確的分析框架和驗證,L3-L4 以及身份載入,需要的是 Agent 特有的設計思維,OS 的經驗在這裡只能提供方向(「protocol 應該薄」「傳遞的內容要壓縮」),但具體怎麼做(inspection map 取代 report、Return Contract 的 token 限制、Hybrid Dispatch 解決身份載入),這些答案在 OS 教科書裡找不到。
我的 Agent Team 在建構過程中,在不知道五層模型的情況下,已經處理了這些 OS 框架解決不了的問題, 五層模型的價值不是教我怎麼設計,而是幫我驗證底層設計是對的,同時讓我看清楚上層的挑戰跟 OS 的差異在哪裡。
同構 vs 異構:最根本的差異
如果要用一句話說清楚 OS IPC 和 Agent Communication 的根本差異,那就是:
OS 管理的是同構的 process,Agent Team 管理的是異構的 specialist。
OS 的 scheduler 可以用同一套規則管所有 process,因為 process 的介面是統一的(都有 PID、都接受 signal、都可以被 kill),但 Agent Team 的 coordinator(GM)不能用同一套規則管所有 Agent,因為每個 Agent 的能力、流程、Context 結構、甚至思考方式都不一樣,GM 需要理解每個 Agent「會產出什麼」「在哪裡看」「用什麼標準判斷品質」, 這些是 per-agent 的知識,不是 per-process 的統一介面。
這也解釋了為什麼我的 dispatch 最後長成了三種模式(A / B-Chain / C-Notify)而不是一個統一的 dispatch mechanism,因為不同的 Agent 組合、不同的任務類型、不同的 Context 流向需求,導致「怎麼 dispatch」這件事本身就有多種可能,每次 dispatch 都是一個判斷:中間產出需不需要留在 GM 的 Context 裡?下一步是固定的還是需要 GM 判斷?這些判斷是 OS 的 scheduler 不需要做的,因為 OS 的 process 不會因為被 dispatch 的方式不同而「載入錯誤的身份」或「把 Context 搞爆」。
或許,OS IPC 能給我的是「前人都怎麼處理」,讓我不用從零開始,可以站在發展幾十年的 OS 設計基礎上,知道 same machine 該用 file、知道 topology 該混合、知道 protocol 內部要輕、外部要夠。
但是,OS IPC 不能給的是「當你的 process 有自己的想法和記憶的時候,溝通這件事的本質會怎麼變?」,因為我們不是在傳 bytes,我們是傳 context,而 context 有品質、有容量、有降級的風險。
所以,這就是為什麼我的 Agent Team 最終長出了 OS 框架裡沒有的東西:inspection map、Return Contract、Hybrid Dispatch、per-agent output domain,這些設計不是在否定 OS 的智慧,而是在 OS 的巨人肩膀上處理一個 AI Agent 需要面對的新問題:你管理的對象會思考,而且每一個想的方式都不一樣。
參考資料
[1] arXiv — Solving Context Window Overflow in AI Agents(context window 對推理品質的影響)
[2] AI Pace — Context Engineering: Mitigating Context Rot in AI Systems(「context 越大,模型可靠性越低」)
[3] FINOS — Multi-Agent Trust Boundary Violations(scope violation 的級聯效應)
[4] Anthropic — Effective Context Engineering for AI Agents
支持這個系列
如果這系列文章對你有幫助,考慮請我喝杯咖啡
請我喝杯咖啡
