目錄
- Context Explosion — 你的五層架構正在塞爆 Context
- 舊的解法為什麼不夠?
- Context Engineering — 真正的解法
- 原則一:JIT(Just-In-Time)載入
- 原則二:Token 預算
- 原則三:Progressive Disclosure(漸進式揭露)
- 原則四:Subagent Return Contract
- 五個常見的 Anti-Patterns
- 1. Context Stuffing(過多的 Context)
- 2. Example Bloat(過多的範例)
- 3. Duplication(重複的 Context)
- 4. Unbounded Returns(無限制的回傳)
- 5. Eager Loading(一開始就全都要)
- 回到最初的問題
- 當 Skill 變成可打包的知識模組
- 參考資料


上一篇我們建立了五層架構:Command → Agent → Tool + Skill → Context 看起來很完整對吧?但如果你真的照這個架構開始建 Agent 系統,你很快就會發現一件事: 真正的瓶頸不在架構設計,在 Context Management 大家都在研究怎麼設計更好的 Agent、怎麼組合更多 Tool、怎麼寫更精巧的 Skill,但這些都是在架高地面的建築,而地基正在裂開、鬆動,甚至可能一夜消失,因為地基就是 Context Window (因為 Context 會爆掉,就像兩層樓的地基撐不住 20 層樓的大廈)
Context Explosion — 你的五層架構正在塞爆 Context
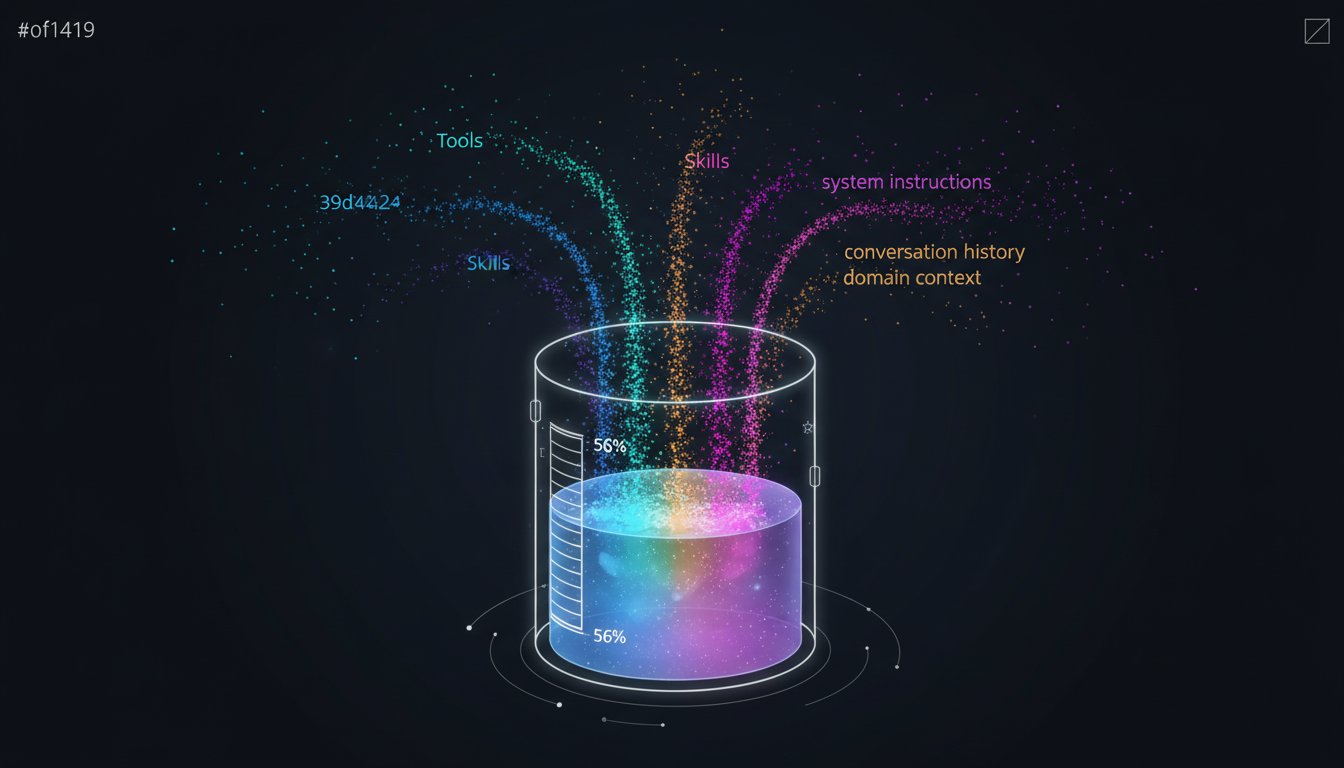
一個 AI Agent 在執行任務時,Context Window 裡同時要塞的東西有下面這些:
- 系統指令(你是誰、你該怎麼做)
- Tool 定義(每個工具的 schema)
- Skill 知識(方法論、框架)
- 領域 Context(公司資料、產品規格)
- 對話歷史(使用者說了什麼、你回了什麼)
- 任務中間狀態(已經做了什麼、還要做什麼)
五層架構的每一層,都在往 Context Window 裡塞東西,而 Context Window 是有限的,如果你是用訂閱方案的 Claude,他的 Context 上限就是 200K tokens(最近有開放 1M Context),聽起來很多? 其實不夠,一個中等複雜的任務,光是 Tool 定義 + 對話歷史就能吃掉一半,我有試過把我工作要用的 Context 放進來,還沒有思考、沒動 Tool(MCP)、沒呼叫 Skill,就先噴了 24% 的 Context,剩下 76% 可用,如果你有開 Auto-Compact,那你剩下 56%(通常會在 78%~83% 之間踩到),更關鍵的是:每一個不必要的 token,都在主動降低系統表現,他不是「浪費 Context 空間」這麼簡單,因為這些 Token 是會干擾 LLM 的注意力的雜訊,導致他做出更差的決策,而你的架構設計的越完整,Context 爆炸得越快!

舊的解法為什麼不夠?
在 Skill System 出現之前,大家怎麼處理這個問題?
- **Prompt Engineering:**把所有知識硬塞進 System Prompt,問題是 Prompt 越來越長、越來越難維護,你的 System Prompt 從 50 行變成 500 行,LLM 的表現反而開始下降,因為他必須從一大堆指令中找到跟當前任務相關的部分
- **RAG:**用向量搜尋把相關文件撈出來塞進 Context,問題是 RAG 解決的是「找到相關資料」,但不解決「怎麼用這些資料」,你可以撈出 10 篇相關文件,但模型還是不知道該用什麼方法論去分析或使用他們
- **Agent Frameworks(**LangChain、AutoGPT 等): 用程式碼定義 Workflow,把步驟寫死,問題:Workflow 寫死就失去了 LLM 的靈活性,而且每個新任務都要寫新的 Workflow,這會讓另外一個東西爆炸,你的維護成本
這三種方法都是在試圖解決 Context 問題,但都只解決了一部分,Skill 的出現,是因為我們需要一種機制,能夠在不塞爆 Context 的前提下,讓 Agent 擁有專業知識
Context Engineering — 真正的解法
如果 Context Explosion 是根本問題,那解法不是「加更多東西」,而是精準控制什麼時候載入什麼、載入多少,這就是 Context Engineering,所以我們要解決的核心問題這時變成了:
找到最小的、高訊號密度的 token 集合,來最大化想要的結果
這時有幾個原則我們可以參考。
原則一:JIT(Just-In-Time)載入
不是所有知識都該一次載入。實務上我們用三層策略:
Always-on (~500 tokens) ← 每次對話都需要的
Task-relevant (~2,000 tokens) ← 根據任務關鍵字載入
Reference (~4,000 tokens) ← 只在明確需要時才載入

Always-on 是你的 CLAUDE.md: 系統身份、核心規則、不變的東西,這個要極度精簡,因為他每次對話都會佔用 Context Task-relevant 是根據任務動態載入的,使用者問財報分析,才載入財報相關的 Skill 和 Context;問程式碼審查,才載入安全審核的方法論 Reference 是最深層的知識,只有當 Agent 明確需要查閱時才載入,大部分對話不會碰到這層
原則二:Token 預算
光有策略不夠,你需要具體的預算,但是在實務中使用的預算會因為你常用的工作模式有所不同,我手上的數字是依照我們公司的工作狀態推估的,這不一定適用所有人,因為這關係到你的工作迭代大約需要幾次的對話。 舉個最簡單的例子,CLAUDE.MD 官方建議不超過 500 行,但在我的工作迭代之下,我預算能給他的只有 60 行(500 Tokens),所以我只能給出一個大概:
- CLAUDE.md → < ~500 tokens — 每次對話都載入,必須極度精簡
- Agent 定義檔 → < ~1,800 Tokens — 一個檔案只關注一件事
- Skill 主文件 → < ~2,500 Tokens — 摘要在主文件,細節用子目錄
- Subagent 回傳 → < ~2,000 tokens — 探索深入,回傳淺層
- Context 文件 → < ~4,300 Tokens — 一個主題一個文件,可獨立載入
這些數字不是隨便定的,在我的使用情境,Token 使用超過這些「預算」,系統表現就會開始下降
原則三:Progressive Disclosure(漸進式揭露)
Skill 不是把一本教科書塞進 Context,Skill 的設計核心是 Progressive Disclosure (分層揭露),只在需要的時候才載入你需要的深度,實務上一個設計良好的 Skill 應該長這樣:
dev-context-engineering/
├── SKILL.md ← 摘要(~300 行),永遠先載入這個
├── principles/ ← WHY:為什麼要這樣做
├── patterns/ ← HOW:具體的模式和做法
├── budgets/ ← LIMITS:token 預算表
├── anti-patterns/ ← DON'T:常見錯誤
└── validation/ ← CHECK:檢查清單Agent 不會一次把整個 Skill 目錄都載入,他先讀 SKILL.md 的摘要,知道這個 Skill 大概在是什麼的知識,當任務需要他的時候就會調用他,而當 Agent 需要更深的知識時,才會去讀 patterns/ 或 budgets/ 裡的細節。這就是為什麼 Skill 不是 Prompt 的結構,Skill 是有結構的知識,可以按照需求/需要載入
原則四:Subagent Return Contract
有一個東西也會佔掉 Context,就是 SubAgent 的回傳資訊,當一個 Agent 派出 SubAgent 去做深度研究時,SubAgent 不應該把所有東西都倒回來,正確的模式是**「探索深入,但只回傳需要的東西」**,SubAgent 用完整的 Context 去探索,但只回傳結構化的摘要(<2,000 tokens),這樣才能保護父 Agent 的 Context Window,這是 Multi-Agent 系統中最常見的問題:SubAgent 做了很多研究,很快樂的把所有東西都回傳,然後塞爆了父 Agent 的 Context,讓後續任務的表現急遽下降
五個常見的 Anti-Patterns

Context Engineering 五個常見的反例(Anti-Pattern):
1. Context Stuffing(過多的 Context)
「先把所有東西載入,反正 Context Window 很大」這是最常見也最致命的錯誤,200K Tokens 看起來很多,但雜訊/噪音會淹沒真正該注意的資訊,LLM 的注意力是有限的,你塞越多不相關的東西,他的處理能力就越差
2. Example Bloat(過多的範例)
在 CLAUDE.md 或 Skill 裡塞超過 2 個 Inline Code Example,範例很佔 Token,而且 LLM 會過度模仿範例的格式,反而失去靈活性
3. Duplication(重複的 Context)
同一個知識出現在 CLAUDE.md、Skill、Context 三個地方,之後維護困難,而且浪費 Token,你應該控制每個知識只存在一個地方
4. Unbounded Returns(無限制的回傳)
Subagent 做完研究,把所有找到的東西都丟回來塞爆 Context,這就是為什麼上面我們說需要 Subagent Return Contract,沒有上限的回傳會摧毀起始父 Agent 的 Context
5. Eager Loading(一開始就全都要)
不管任務是什麼,一開始就把所有 Skill 和 Context 都載入,任務還沒開始,可用的 Context 就剩下 70%,真正有效的做法是 JIT,先看任務是什麼,再決定載入什麼
回到最初的問題
上一篇最後問了一個問題:為什麼幾乎所有 AI Agent 系統都在加入 Skill system? 現在答案應該很清楚了,不是因為 LLM 不夠聰明,是因為 Context Window 是有限的,你不可能把所有知識都塞進 Context,而 Skill 提供了一個機制:
- 結構化的知識 — 不是一大坨文字,而是有目錄結構的知識模組
- Progressive Disclosure — 先載摘要,需要時再載細節
- JIT 載入 — 根據任務動態決定載入什麼
- 可復用 — 同一個 Skill 可以被不同 Agent 在不同任務中使用
本質上,Skill 就是一種 expert module,讓一個通用的 LLM,在需要的時候,變成某個領域的專家。而 Context Engineering 就是管理這些 expert module 的作業系統
當 Skill 變成可打包的知識模組


如果你是工程師,你會發現 Skill 的設計很像:
- VSCode Extensions
- Browser Plugins
- NPM Packages
每個 Skill 就是一個 **Domain Expertise Package,**打包好的專業知識,可以安裝、可以更新、可以分享 但這裡有一個關鍵差異,傳統的 plugin 是程式碼,Skill 是知識,Plugin 告訴電腦「怎麼執行」,Skill 告訴 AI「怎麼思考」 所以當 Skill 變成可打包、可分享的知識模組,AI 就開始出現一種新的東西:Plugin Economy
未來可能會有:
- Legal Skill — 讓 AI 用律師的方式審查合約
- Security Skill — 讓 AI 用資安專家的方式做滲透測試
- Finance Skill — 讓 AI 用分析師的方式解讀財報
但這也帶來一個新問題:誰定義這個生態系的規則?誰控制 Skill 的標準?
目前 MCP 正在解決 Tool 的跨平台問題,讓不同 Runtime 都能用同一套工具,但 Skill 的跨平台問題還沒有標準答案(但 Codex 投靠 Claude 了),這意味著,未來 AI 的競爭可能不只是 model 的競爭 — 而是 Skill ecosystem 標準的競爭,這是下一篇要談的。
參考資料
[1] Anthropic: “Effective Context Engineering for AI Agents” — “Good context engineering means finding the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome” https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
[2] “Lost in the Middle: How Language Models Use Long Contexts” — Liu et al. (Stanford/TACL 2024) — 學術論文證明模型在長 context 中段資訊的效能顯著下降 https://arxiv.org/abs/2307.03172
[3] Chroma Research: “Context Rot” — 測試 18 個前沿模型,所有模型隨輸入長度增加效能都下降;三個疊加機制:lost-in-middle、attention dilution、distractor interference https://research.trychroma.com/context-rot
[4] Andrej Karpathy on Context Engineering — “When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window” https://x.com/karpathy/status/1937902205765607626
[5] Anthropic: “Equipping Agents for the Real World with Agent Skills” — 描述三層 progressive disclosure:啟動時載入描述,任務相關時才載入完整 SKILL.md https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills
[6] Martin Fowler: “Context Engineering for Coding Agents” — “An agent’s effectiveness goes down when it gets too much context”;模型在 100 萬 token 附近達到效能天花板 https://martinfowler.com/articles/exploring-gen-ai/context-engineering-coding-agents.html
[7] Simon Willison: “Context Engineering” — 討論 Context Quarantine、Context Pruning、Context Summarization 等具體技術 https://simonwillison.net/2025/Jun/27/context-engineering/
支持這個系列
如果這系列文章對你有幫助,考慮請我喝杯咖啡
請我喝杯咖啡
